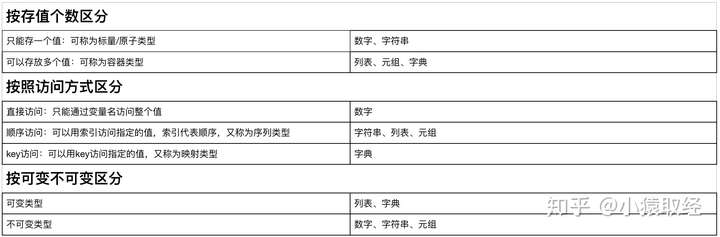
1
2
3
4
5
6
7
8
9
10
11
12
13
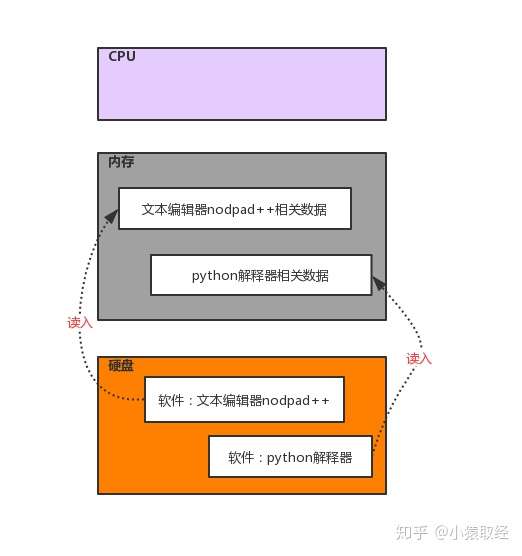
14
15
16
17
18
19
20
21
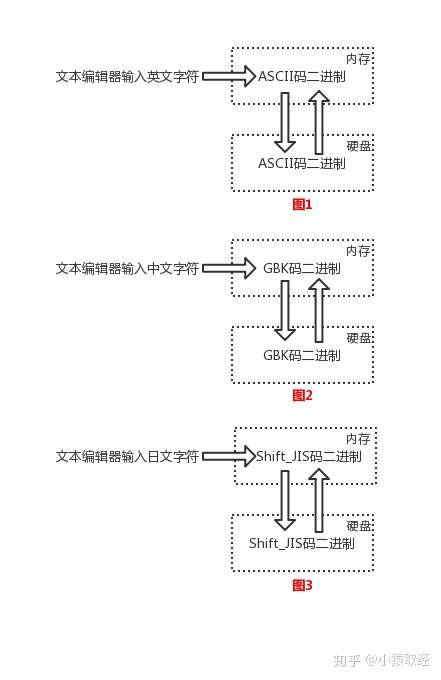
22
23
24
25
26
27
28
29
30
31
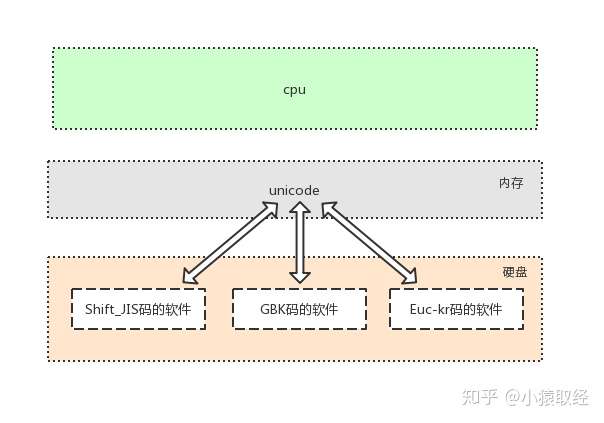
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
|
>>> my_friends=['tony','jason','tom',4,5]
>>> my_friends[0]
tony
>>> my_friends[-1]
5
>>> my_friends = ['tony','jack','jason',4,5]
>>> my_friends[1] = 'martthow'
>>> my_friends
['tony', 'martthow', 'jason', 4, 5]
>>> my_friends[0:4]
['tony', 'jason', 'tom', 4]
>>> my_friends[0:4:2]
['tony', 'tom']
>>> len(my_friends)
5
>>> 'tony' in my_friends
True
>>> 'xxx' not in my_friends
True
>>> l1 = ['a','b','c']
>>> l1.append('d')
>>> l1
['a', 'b', 'c', 'd']
>>> l1.extend(['a','b','c'])
>>> l1
['a', 'b', 'c', 'd', 'a', 'b', 'c']
>>> l1.insert(0,"first")
>>> l1
['first', 'a', 'b', 'c', 'alisa', 'a', 'b', 'c']
>>> l = [11,22,33,44]
>>> del l[2]
>>> l
[11,22,44]
>>> l = [11,22,33,22,44]
>>> res=l.pop()
>>> res
44
>>> res=l.pop(1)
>>> res
22
>>> l = [11,22,33,22,44]
>>> res=l.remove(22)
>>> print(res)
None
>>> l = [11,22,33,44]
>>> l.reverse()
>>> l
[44,33,22,11]
>>> l = [11,22,3,42,7,55]
>>> l.sort()
>>> l
[3, 7, 11, 22, 42, 55]
>>> l = [11,22,3,42,7,55]
>>> l.sort(reverse=True)
>>> l
[55, 42, 22, 11, 7, 3]
>>> l1=[1,2,3]
>>> l2=[2,]
>>> l2 > l1
True
>>> s1='abc'
>>> s2='az'
>>> s2 > s1
True
>>> l = ['A','z','adjk','hello','hea']
>>> l.sort()
>>> l
['A', 'adjk', 'hea', 'hello','z']
for line in my_friends:
print(line)
'tony'
'jack'
'jason'
4
5
|
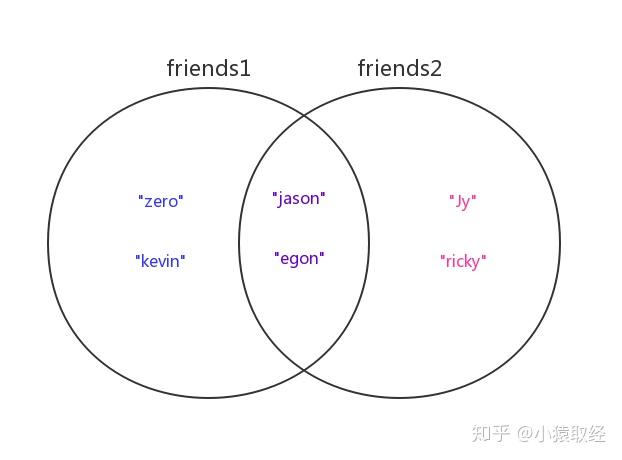
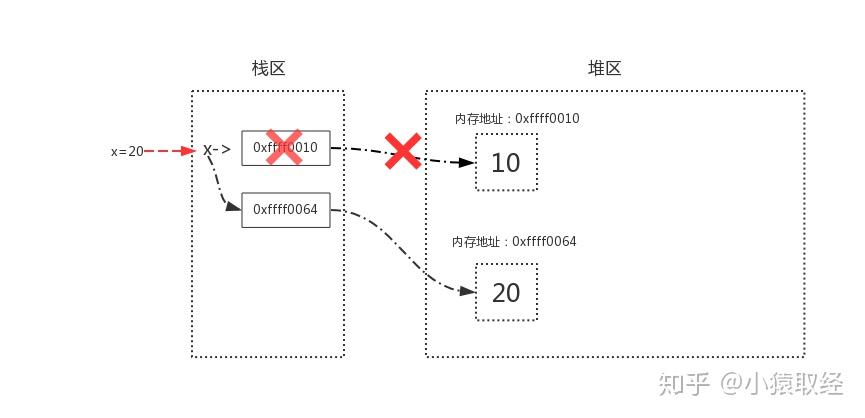
 View Code
View Code