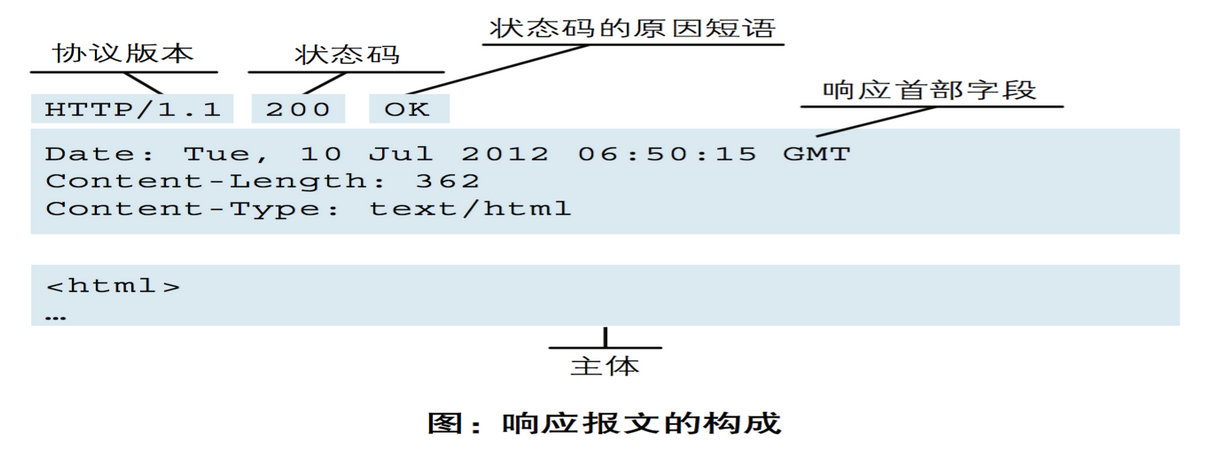
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| $('#i1')
r.fn.init [div#i1.container]
$('h2')
r.fn.init [h2, prevObject: r.fn.init(1)]
$('input')
r.fn.init(9) [input#exampleInputEmail1.form-control, input#exampleInputPassword1.form-control, input#exampleInputFile, input, input, input, input, input#optionsRadios1, input#optionsRadios2, prevObject: r.fn.init(1)]
$('.c1')
r.fn.init(2) [h1.c1, h1.c1, prevObject: r.fn.init(1)]
$('.btn-default')
r.fn.init [button#btnSubmit.btn.btn-default, prevObject: r.fn.init(1)]
$('.c1,h2')
r.fn.init(3) [h1.c1, h1.c1, h2, prevObject: r.fn.init(1)]
$('.c1,#p3')
r.fn.init(3) [h1.c1, h1.c1, p#p3.divider, prevObject: r.fn.init(1)]
$('.c1,.btn')
r.fn.init(11) [h1.c1, h1.c1, a.btn.btn-primary.btn-lg, button.btn.btn-warning, button.btn.btn-danger, button.btn.btn-warning, button.btn.btn-danger, button.btn.btn-warning, button.btn.btn-danger, button#btnSubmit.btn.btn-default, a.btn.btn-success, prevObject: r.fn.init(1)]
$('form').find('input')
r.fn.init(3) [input#exampleInputEmail1.form-control, input#exampleInputPassword1.form-control, input#exampleInputFile, prevObject: r.fn.init(1)]
$('label input')
r.fn.init(6) [input, input, input, input, input#optionsRadios1, input#optionsRadios2, prevObject: r.fn.init(1)]
$('label+input')
r.fn.init(3) [input#exampleInputEmail1.form-control, input#exampleInputPassword1.form-control, input#exampleInputFile, prevObject: r.fn.init(1)]
$('#p2~li')
r.fn.init(8) [li, li, li, li, li, li, li, li, prevObject: r.fn.init(1)]
$('#f1 input:first')
r.fn.init [input#exampleInputEmail1.form-control, prevObject: r.fn.init(1)]
$('#my-checkbox input:last')
r.fn.init [input, prevObject: r.fn.init(1)]
$('#my-checkbox input[checked!="checked"]')
r.fn.init(3) [input, input, input, prevObject: r.fn.init(1)]0: input1: input2: inputlength: 3prevObject: r.fn.init [document]__proto__: Object(0)
$('label:has("input")')
r.fn.init(6) [label, label, label, label, label, label, prevObject: r.fn.init(1)]
|


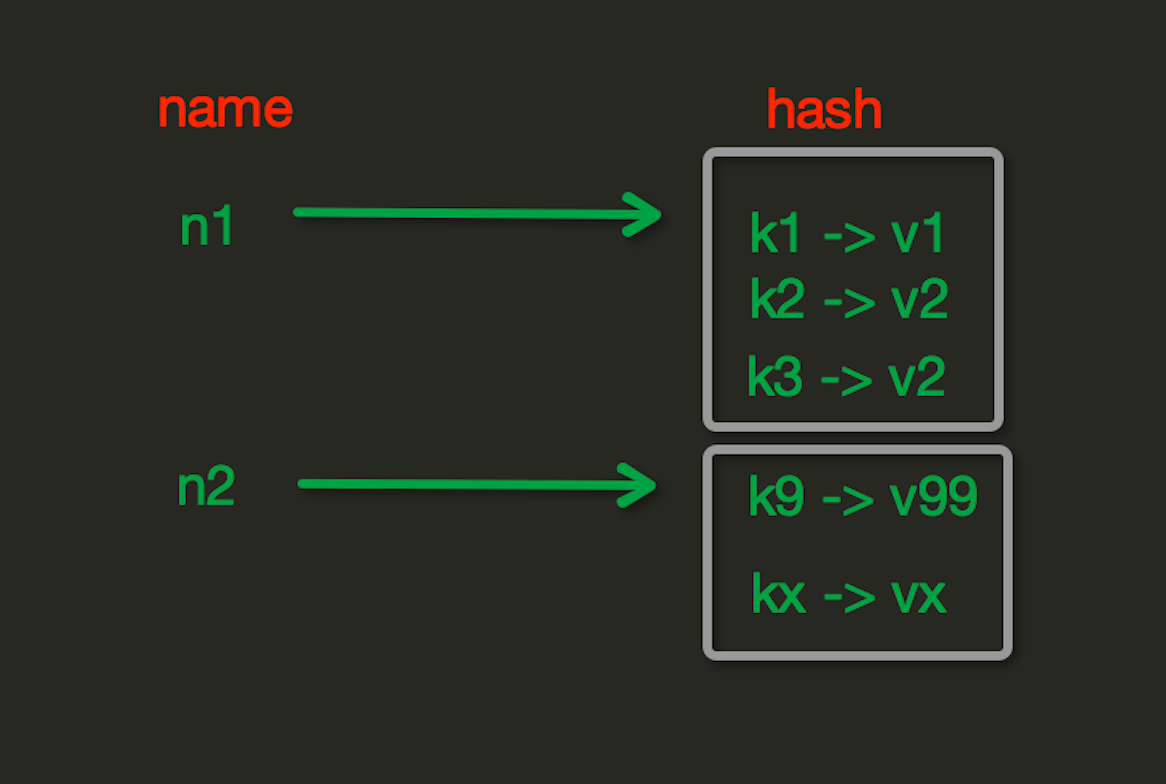
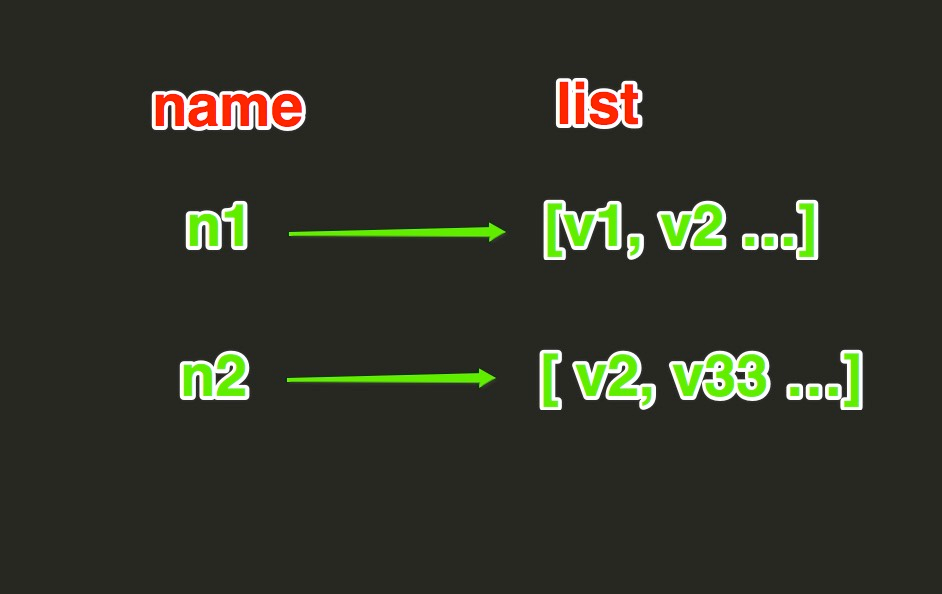

 等。
等。