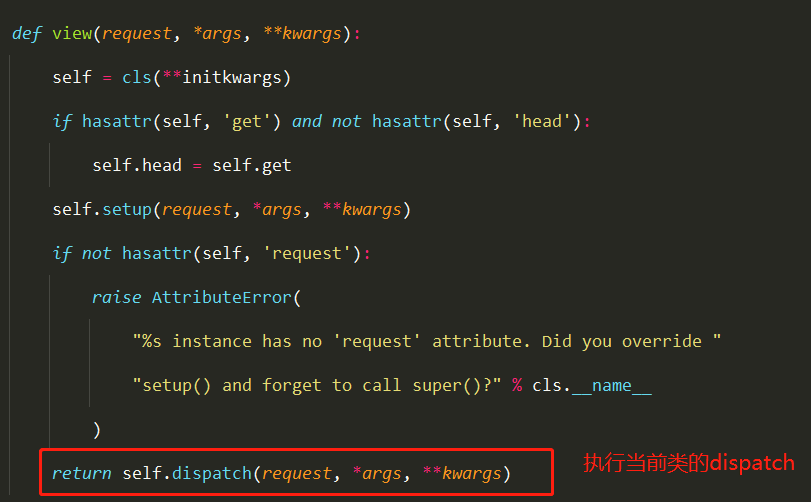
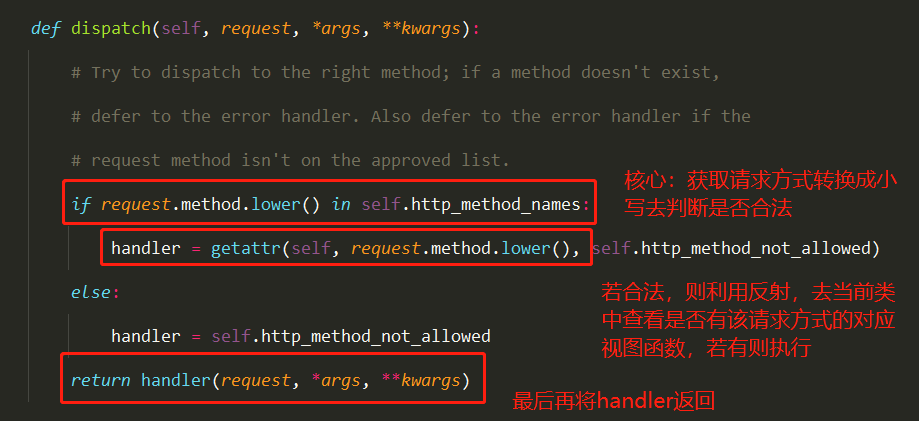
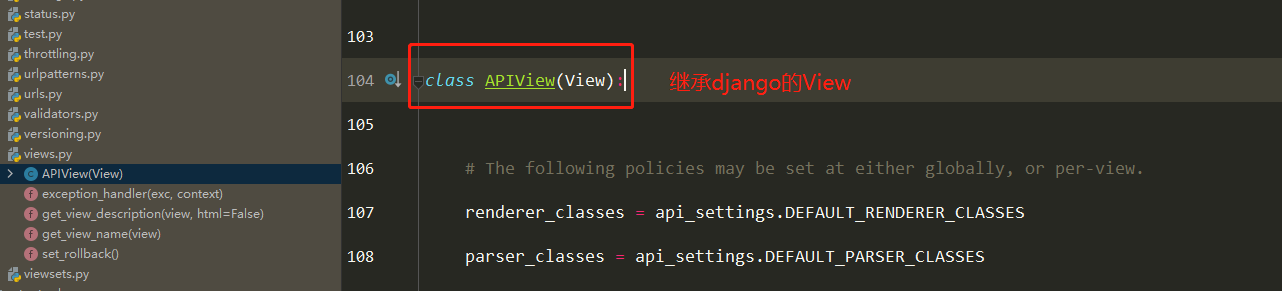
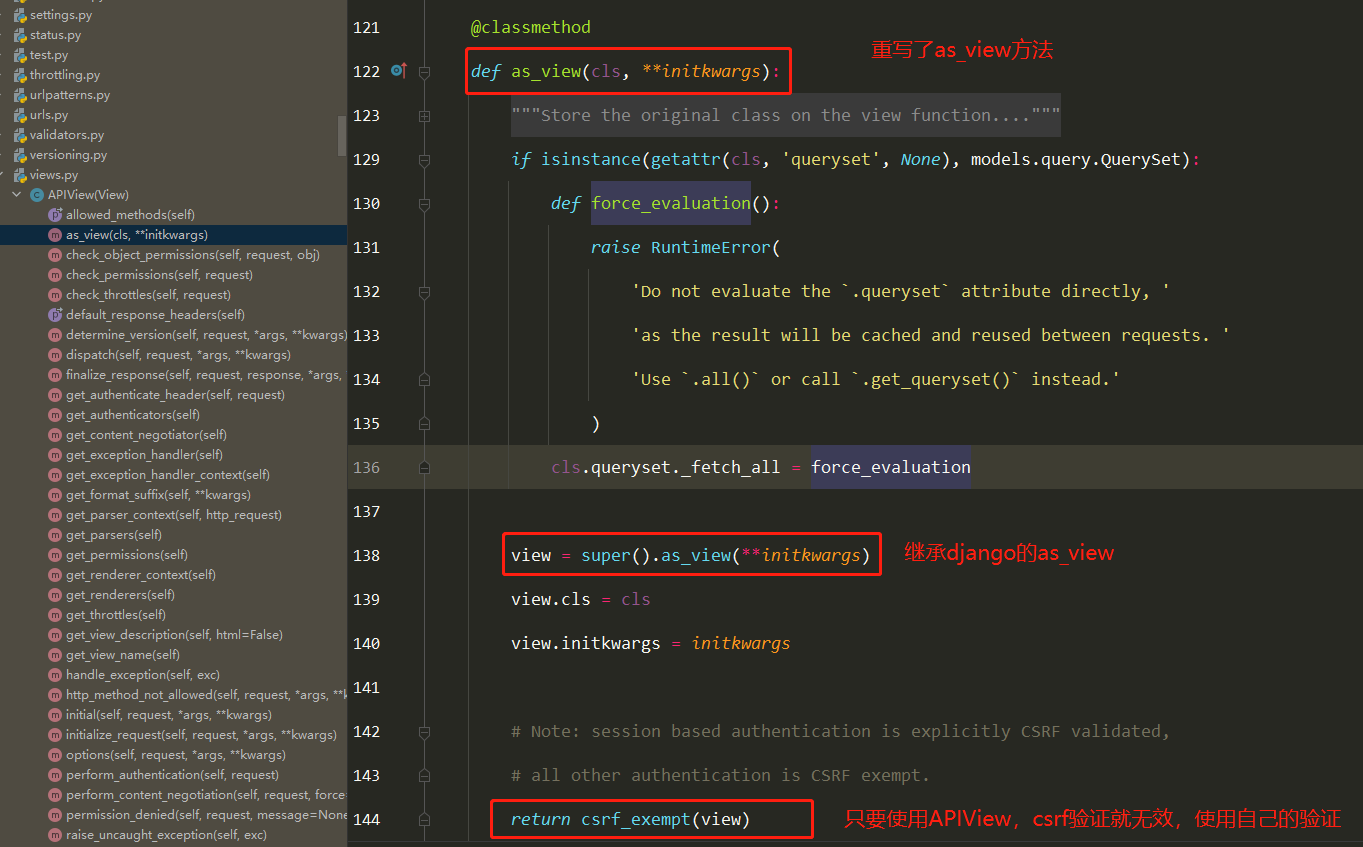
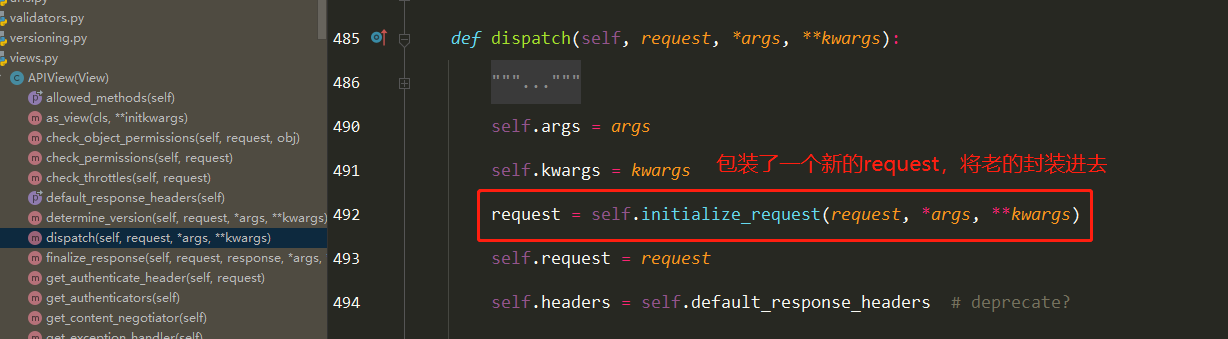
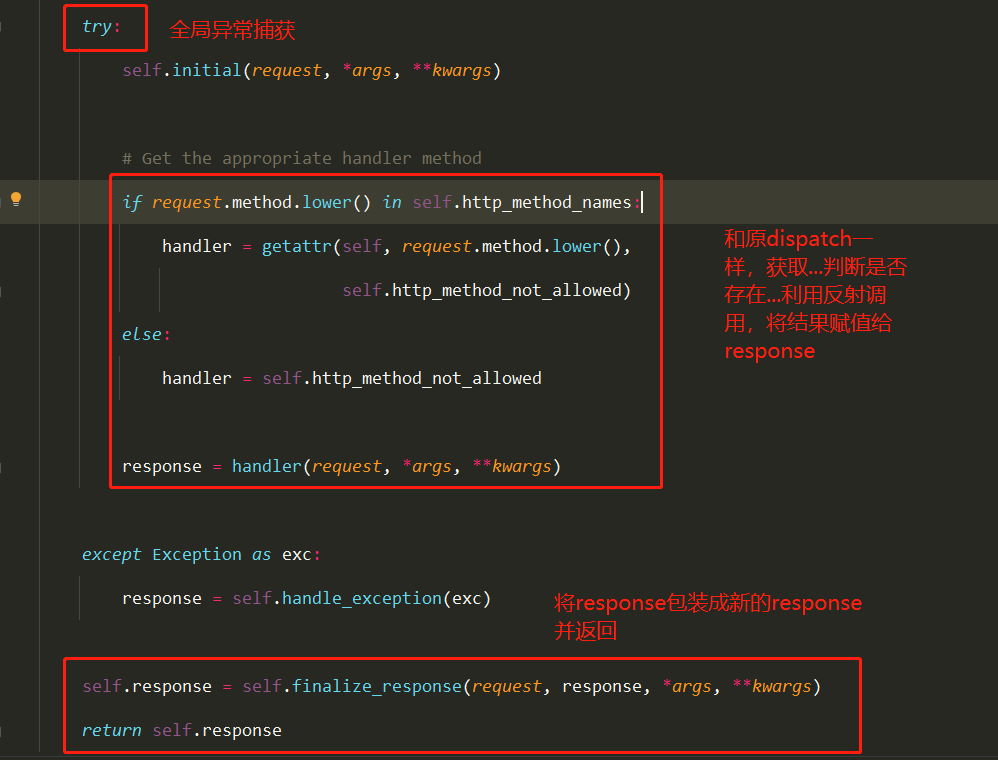
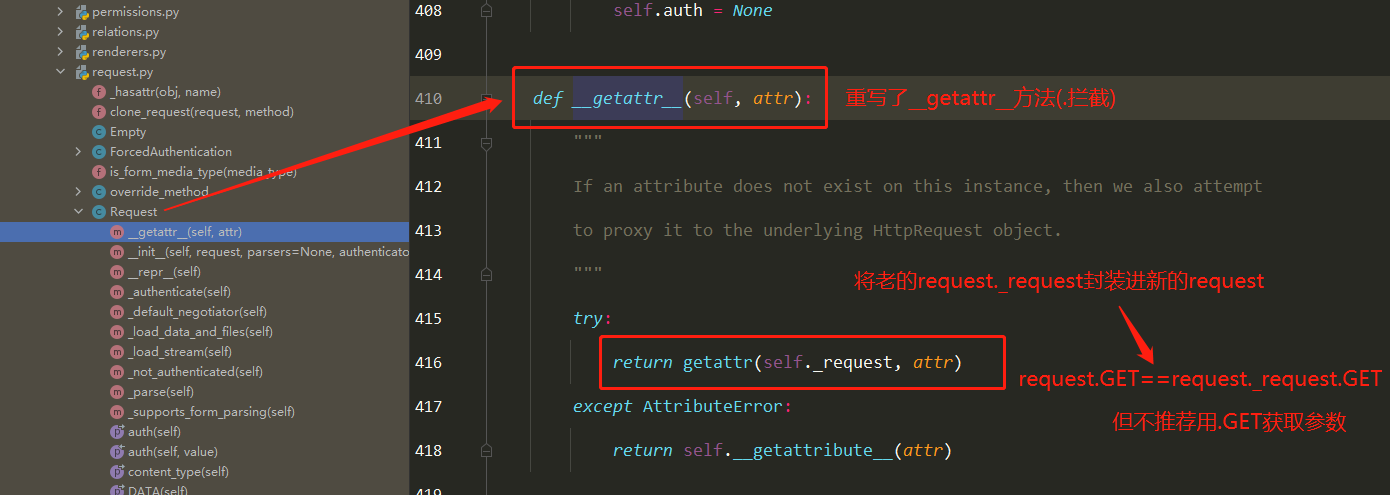
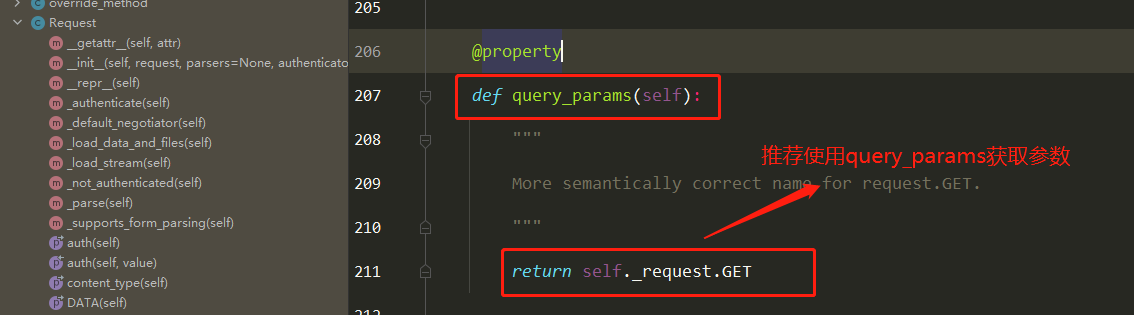
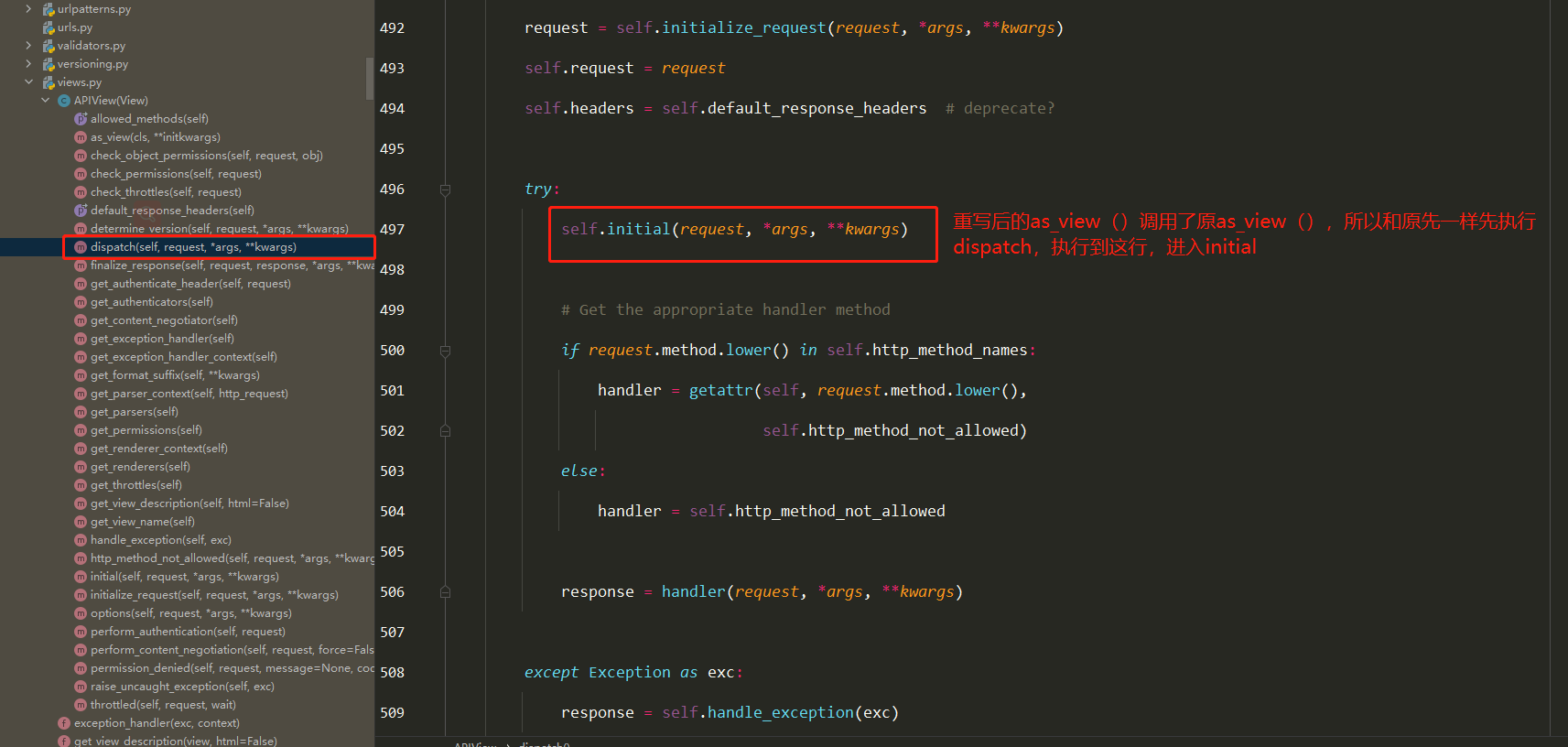
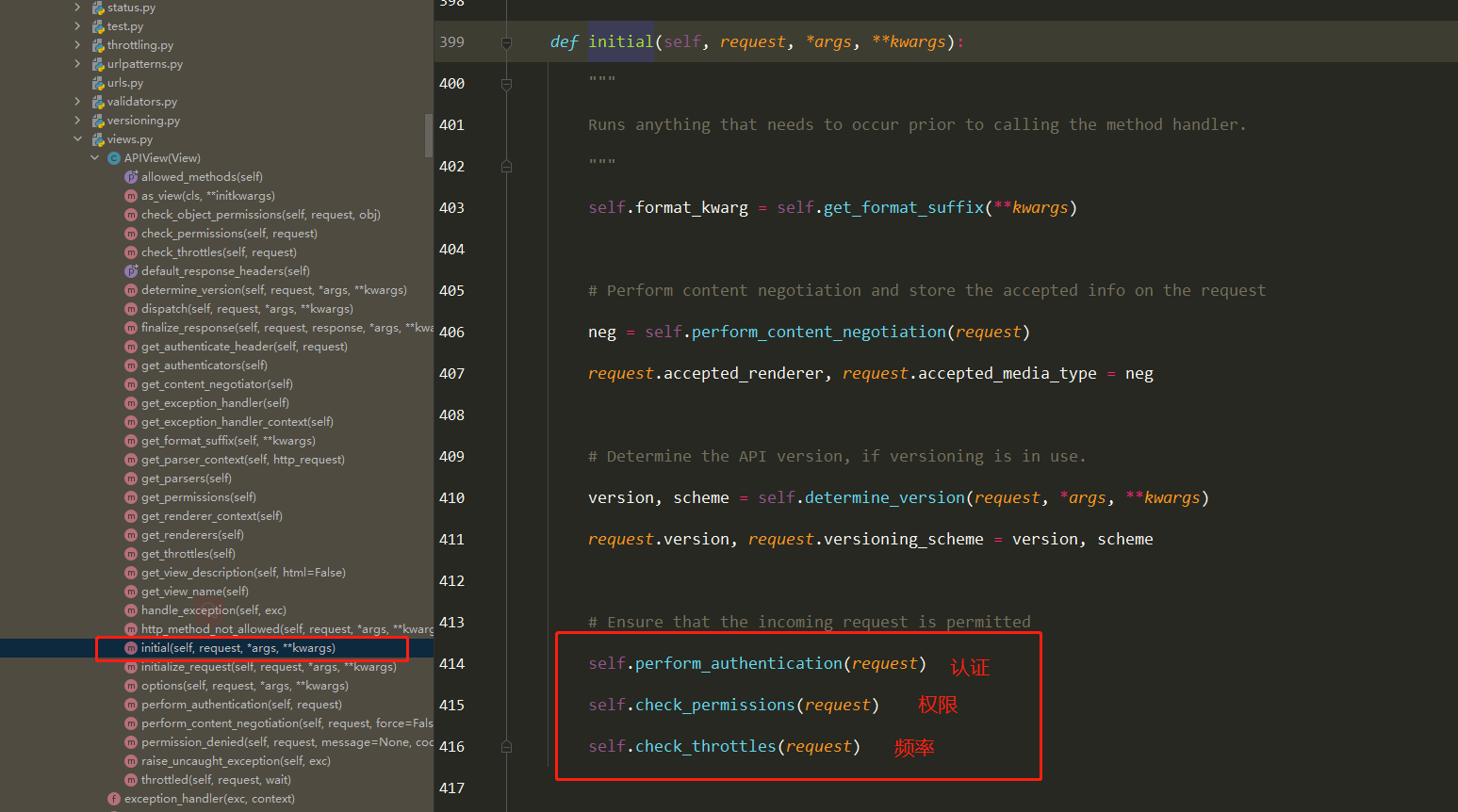
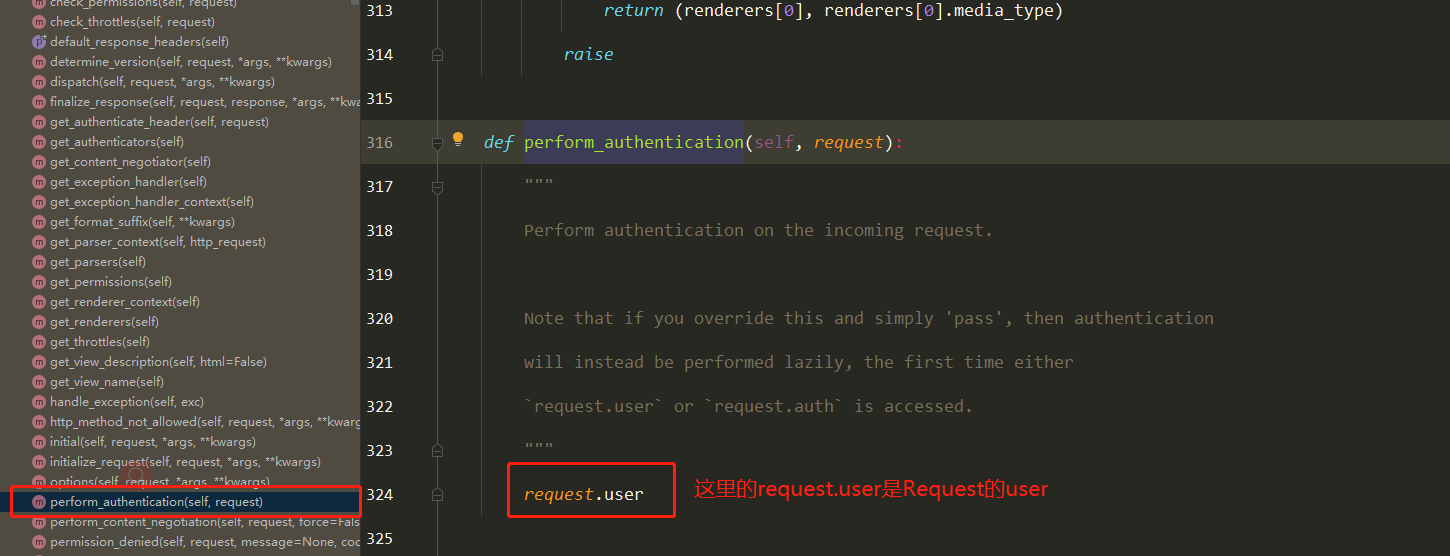
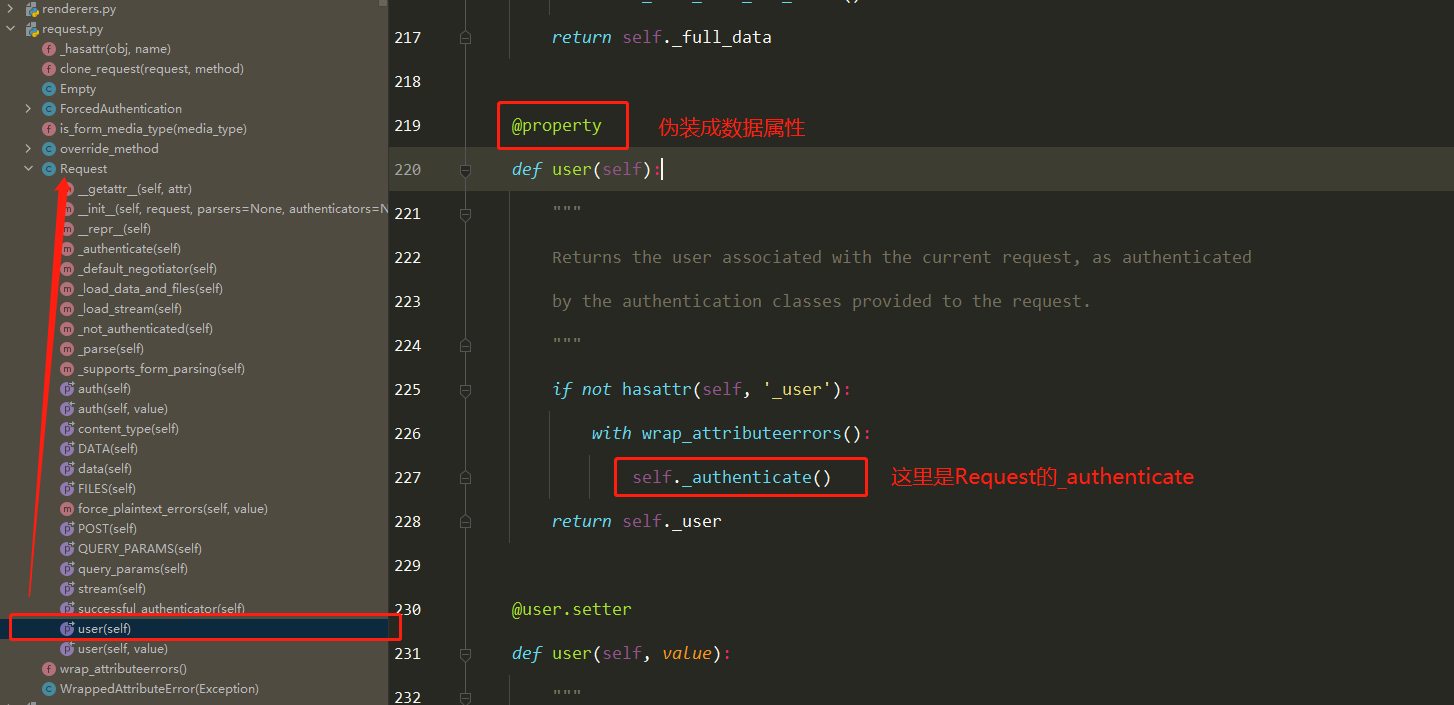
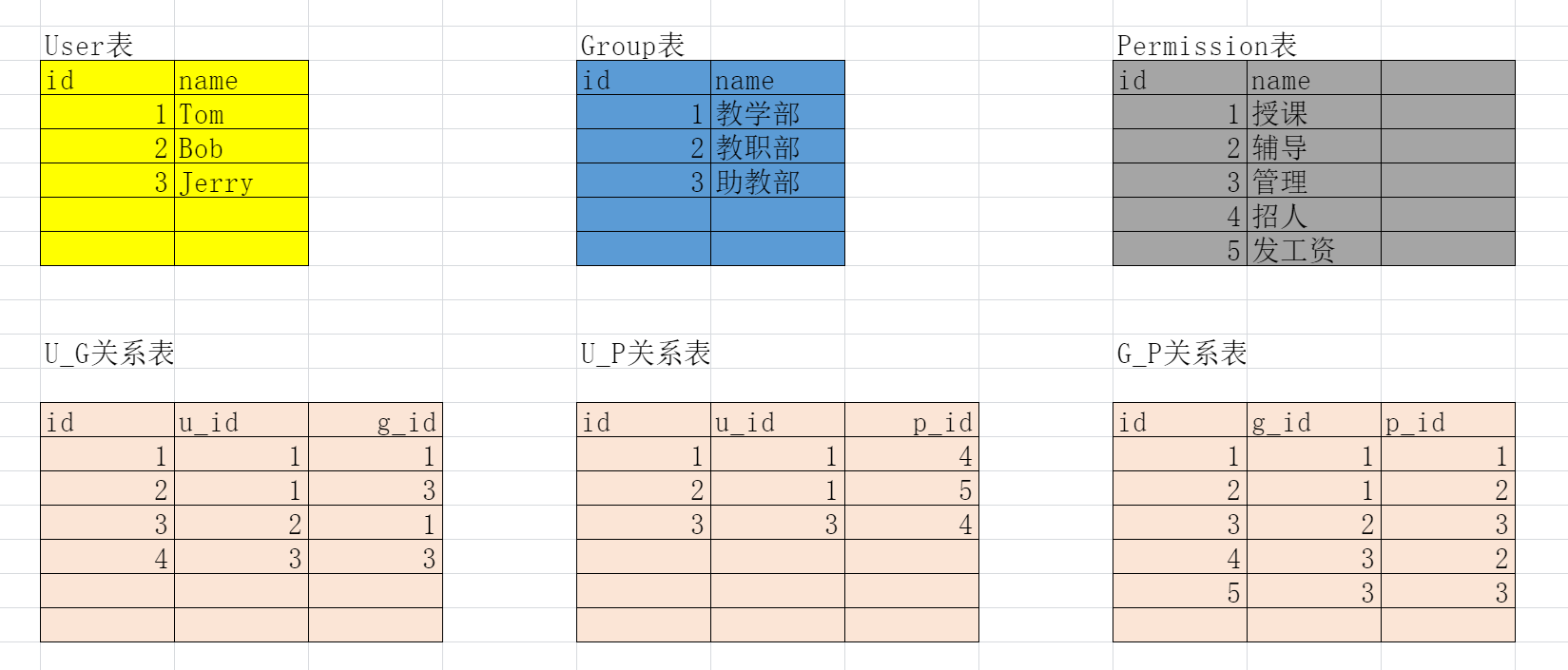
Docker学习
Docker概述
Docker安装
Docker命令
Docker镜像
容器的数据卷
DockerFIle
Docker网络原理
IDEA整合Docker
Docker Compose
Docker Swarm
CI\CD jenkins
Docker概述 Docker为什么会出现? 一款产品:开发-上线 两套环境,应用配置!
开发 — 运维 问题: 项目在我的电脑上可以运行!版本更新,导致服务不可用!对于运维来说,考验就十分大
环境配置是十分的麻烦.每一个机器都要部署环境(集群Redis, ES, Hadoop…)! 费时费力
发布一个项目(Jar+ (Redis,ES, Hadoop)),项目为什么不带上环境安装打包
在服务器上配置十分麻烦,不能够跨平台
Windows开发,发布到Linux
传统开发: 开发人员做项目,运维人员做部署
现在: 开发打包部署上线,一套流程做完
java – apk – 发布(应用商店) –使用者使用apk– 安装即用
java — jar(环境) — 打包上线自带环境(镜像) —(Docker仓库: 商店) — 下载我们发布的镜像 — 直接运行即可
Docker是基于Go语言开发的开源项目!
官网: https://www.docker.com/
文档地址: https://docs.docker.com/get-docker/
仓库地址: https://hub.docker.com/
Docker能干嘛?
之前的虚拟机技术
虚拟机技术缺点:
容器化技术
容器化技术不是一个完整的操作系统
比较Docker和虚拟机技术的不同
传统的虚拟机,虚拟出一条硬件,运行一个完整的操作系统,然后在这个系统上安装和运行软件
容器内的应用直接运行在宿主机的内容,容器是没有自己的内核的,也没有虚拟我们的硬件,所以就轻便了
每个容器间都是互相隔离的,每一个容器内都有一个属于自己的文件系统,互不影响
DevOps(开发,运维)
更快速的交付和部署
传统: 一堆帮助文档,安装程序
Docker: 一键运行打包镜像发布测试
更便捷的升级和扩缩容
使用了Docker之后,我们部署应用就像搭积木一样!
项目打包为一个镜像,扩展,服务器A!服务器B
更简单的系统运维
在容器化之后,我们开发,测试环境都是高度一致的
更高效的计算资源利用:
Docker是内核级别的虚拟化, 可以在一个物理机上运行很多的容器实例! 服务器的性能可以被压榨到极致
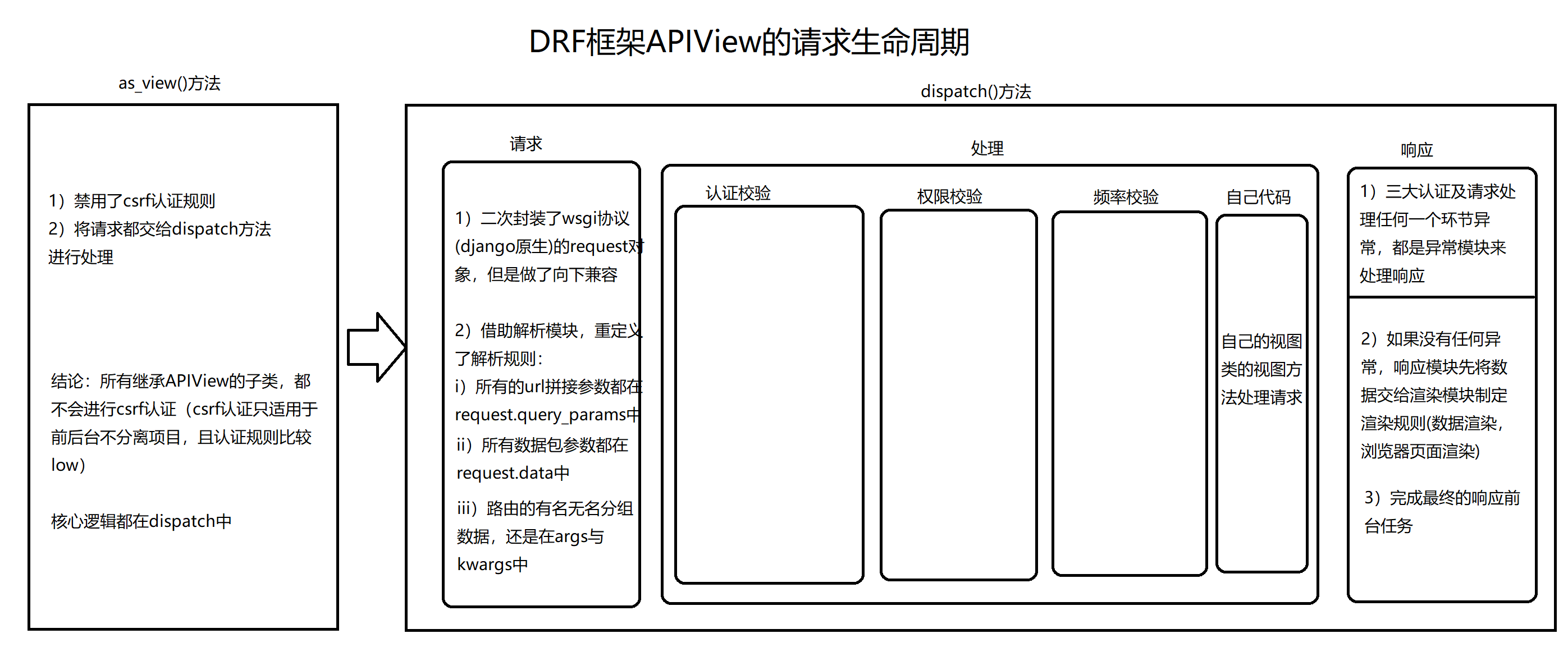
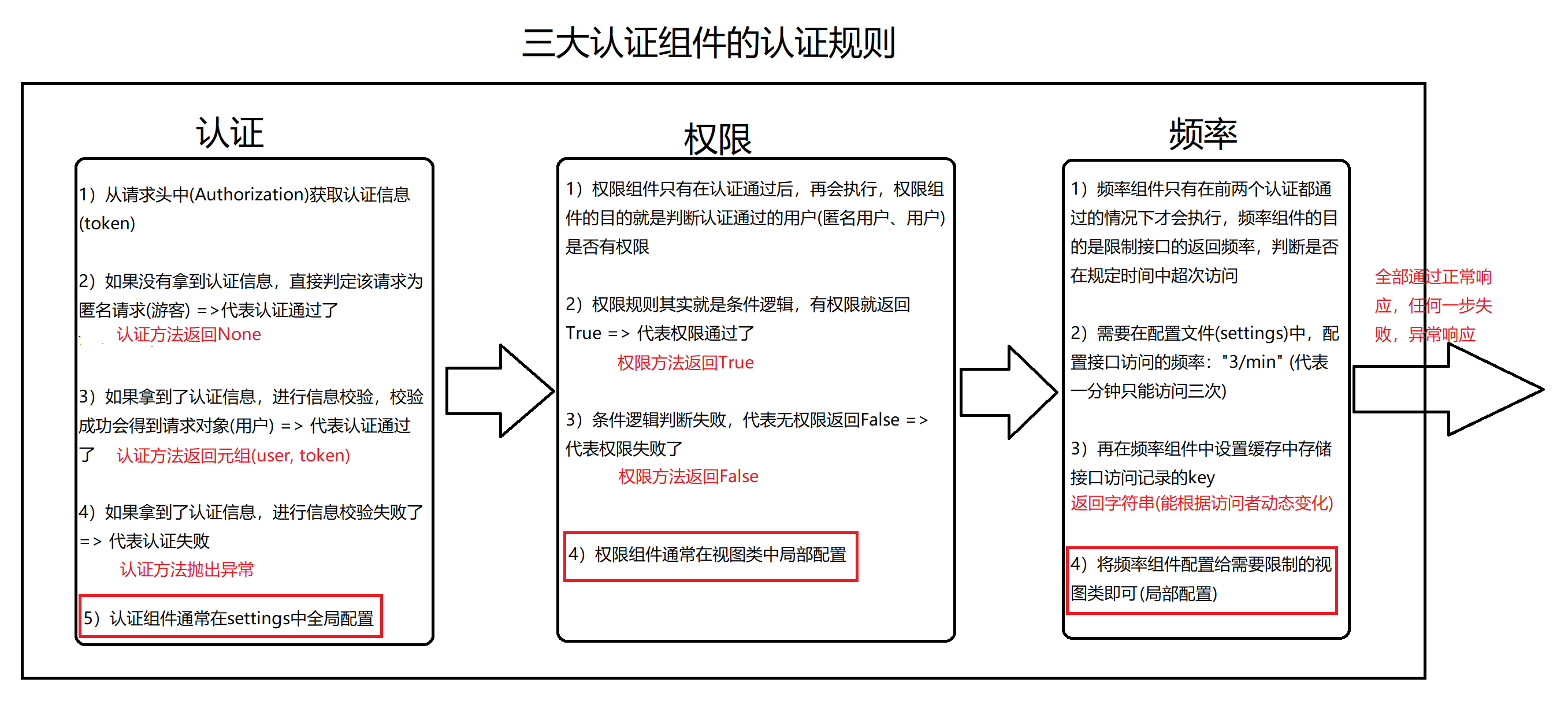
Docker安装 Docker的基本组成
镜像(image) :
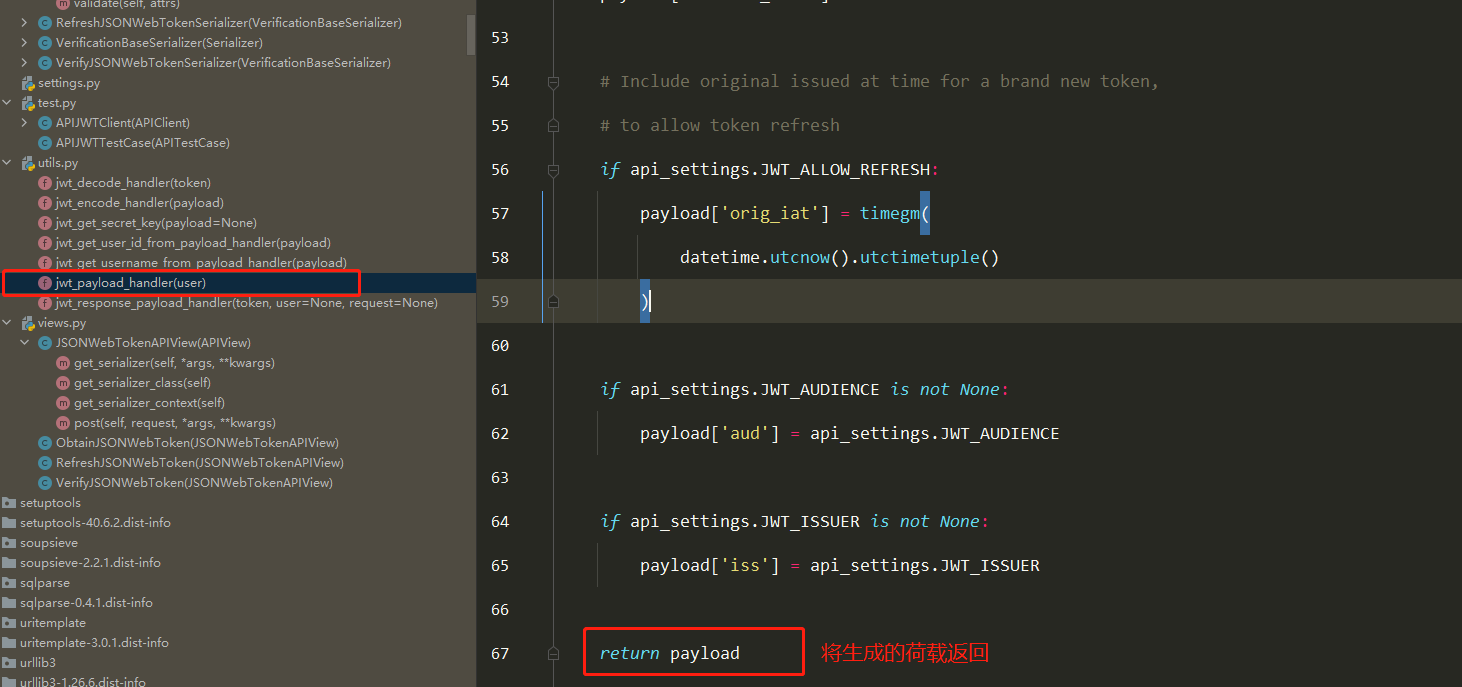
docker镜像好比一个模板,可以通过这个模板来创建容器服务,tomcat镜像===>run ==>tomcat01容器(提供服务器)
通过这个镜像可以创建多个容器(最终服务运行或者项目运行就是在容器中的)
容器(container) :
Docker利用容器技术,独立运行一个或者一个组应用,通过镜像来创建的
启动,停止,删除,基本命令!
仓库(repository) :
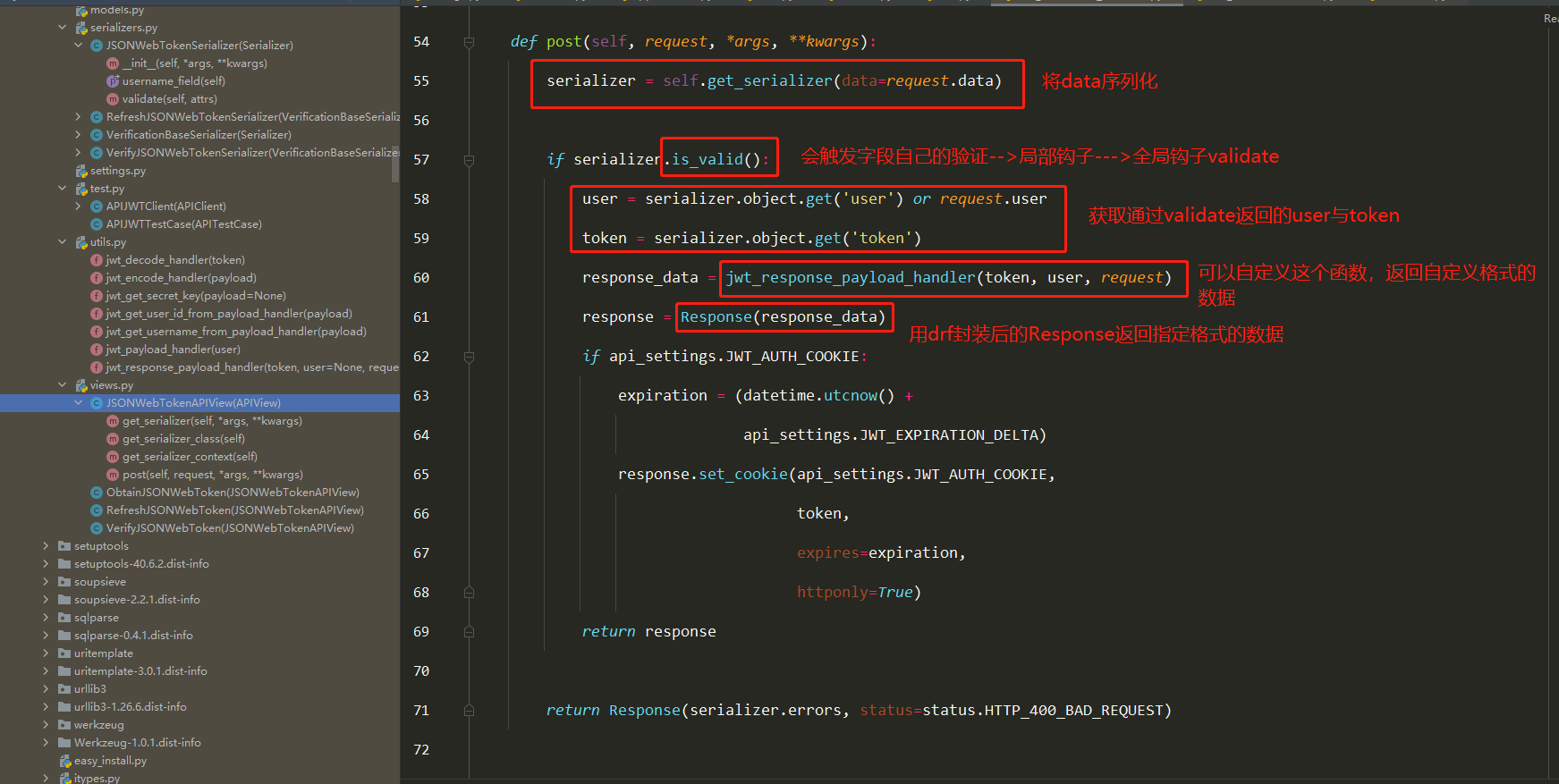
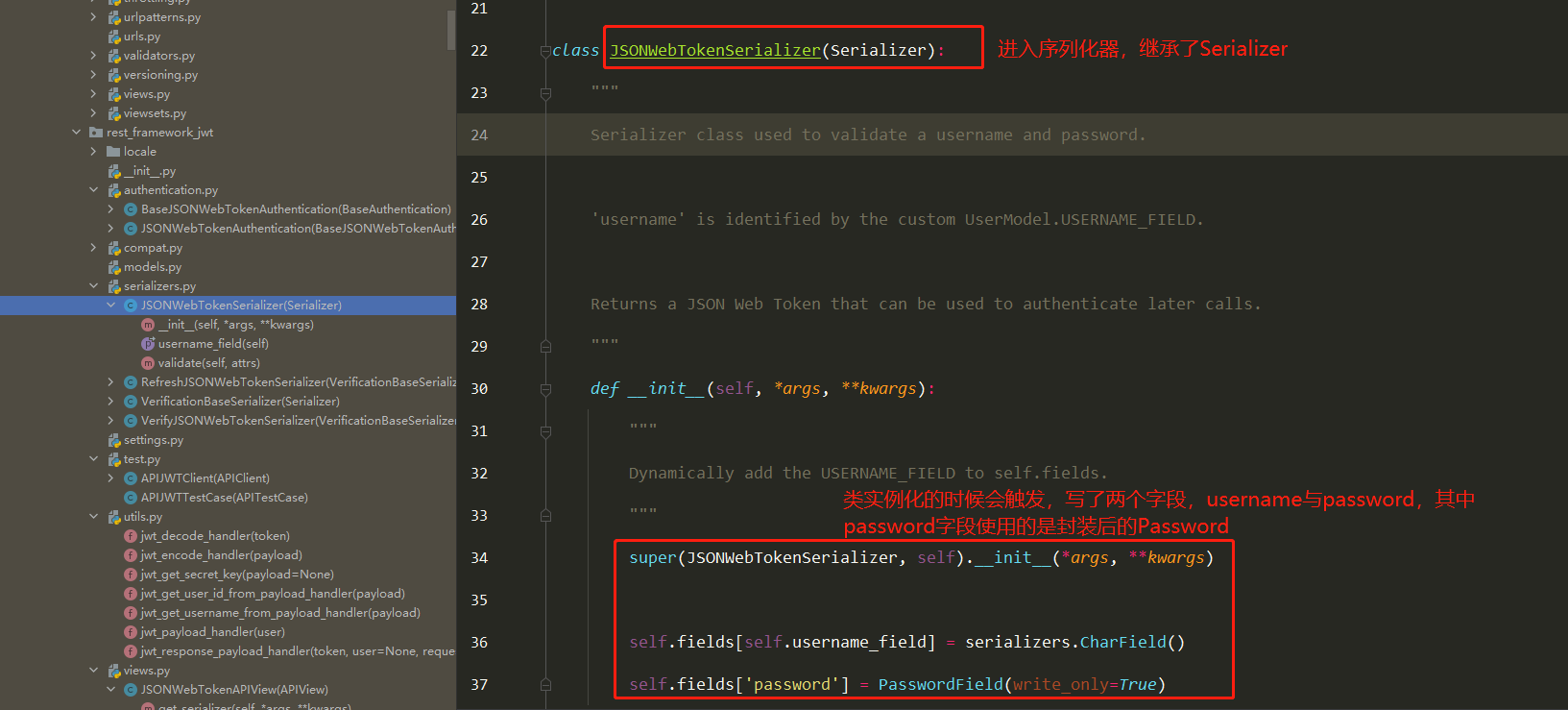
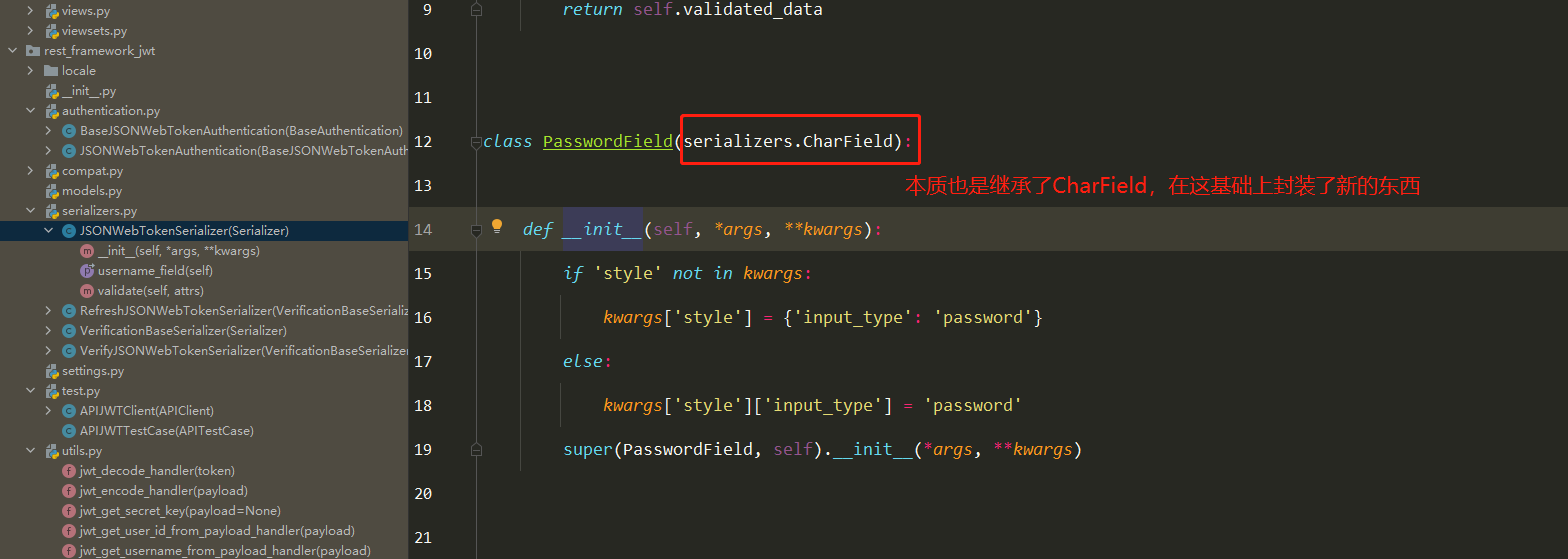
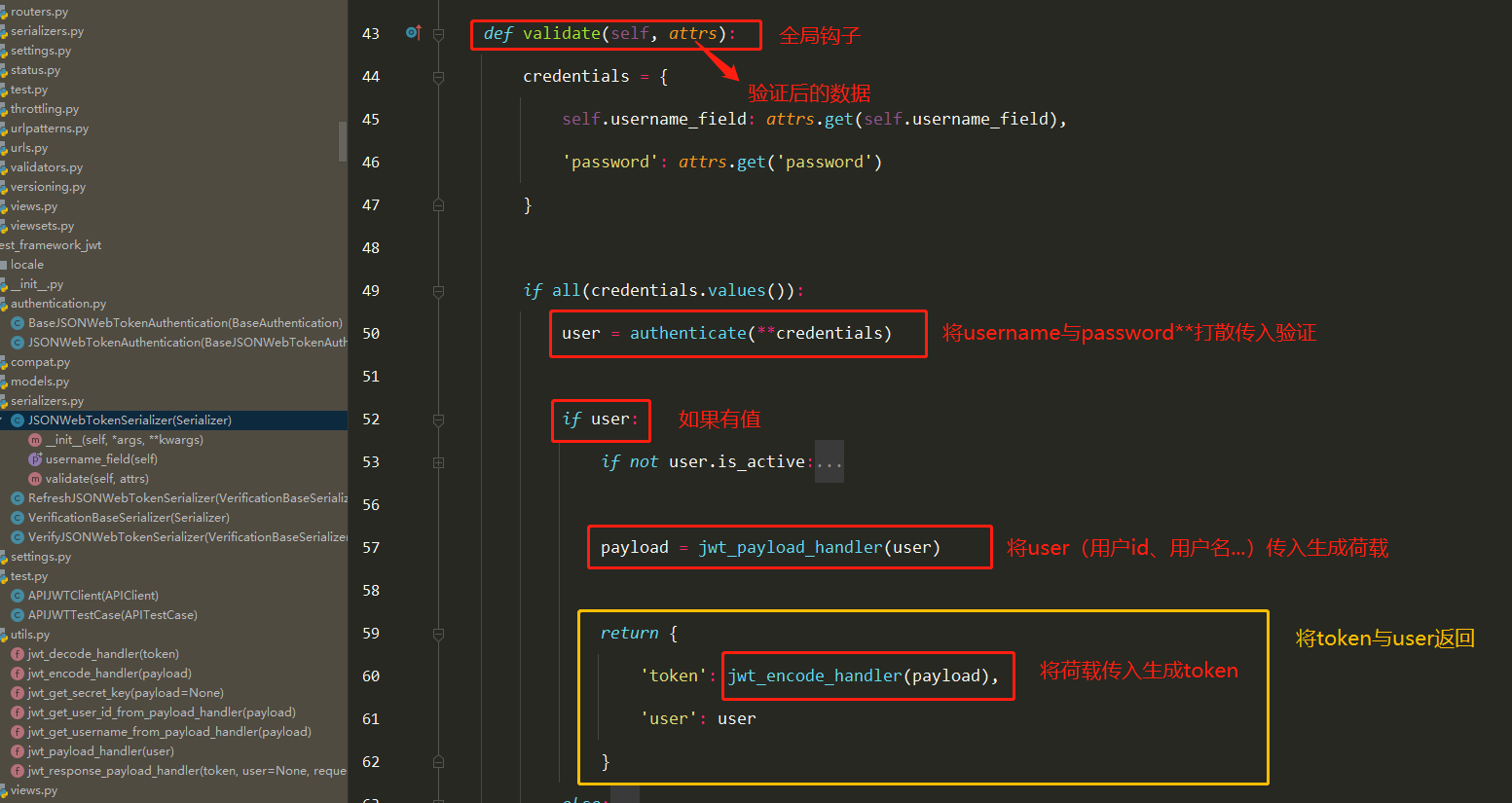
仓库就是存放镜像的地方!
仓库分为共有仓库和私有仓库
Docker Hub(默认是国外的)
阿里云… 都有容器服务器(配置镜像加速)
安装Docker
环境准备
需要会一点点Linux基础
CentOS7
使用Xshell连接远程服务器
环境查看
1 2 3 [root@iZ2zeheduaqlfxyl598si8Z /] 3.10.0-1062.18.1.el7.x86_64
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@CZP ~] NAME="CentOS Linux" VERSION="7 (Core)" ID="centos" ID_LIKE="rhel fedora" VERSION_ID="7" PRETTY_NAME="CentOS Linux 7 (Core)" ANSI_COLOR="0;31" CPE_NAME="cpe:/o:centos:centos:7" HOME_URL="https://www.centos.org/" BUG_REPORT_URL="https://bugs.centos.org/" CENTOS_MANTISBT_PROJECT="CentOS-7" CENTOS_MANTISBT_PROJECT_VERSION="7" REDHAT_SUPPORT_PRODUCT="centos" REDHAT_SUPPORT_PRODUCT_VERSION="7"
安装Docker
查看帮助文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 $ sudo yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-engine yum install -y yum-utils yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo yum-config-manager \ --add-repo \ https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum makecache fast sudo yum install docker-ce docker-ce-cli containerd.io systemctl start docker docker version
下载镜像
docker pull [要下载的软件]
查看下载的镜像
docker images
卸载docker
1 2 3 yum remove docker-ce docker-ce-cli containerd.io rm -rf /var/lib/docker
阿里云配置Docker镜像加速
执行命令
1 2 3 4 5 6 7 8 9 10 11 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors" : ["阿里云镜像加速地址" ] } EOF sudo systemctl daemon-reload sudo systemctl restart docker
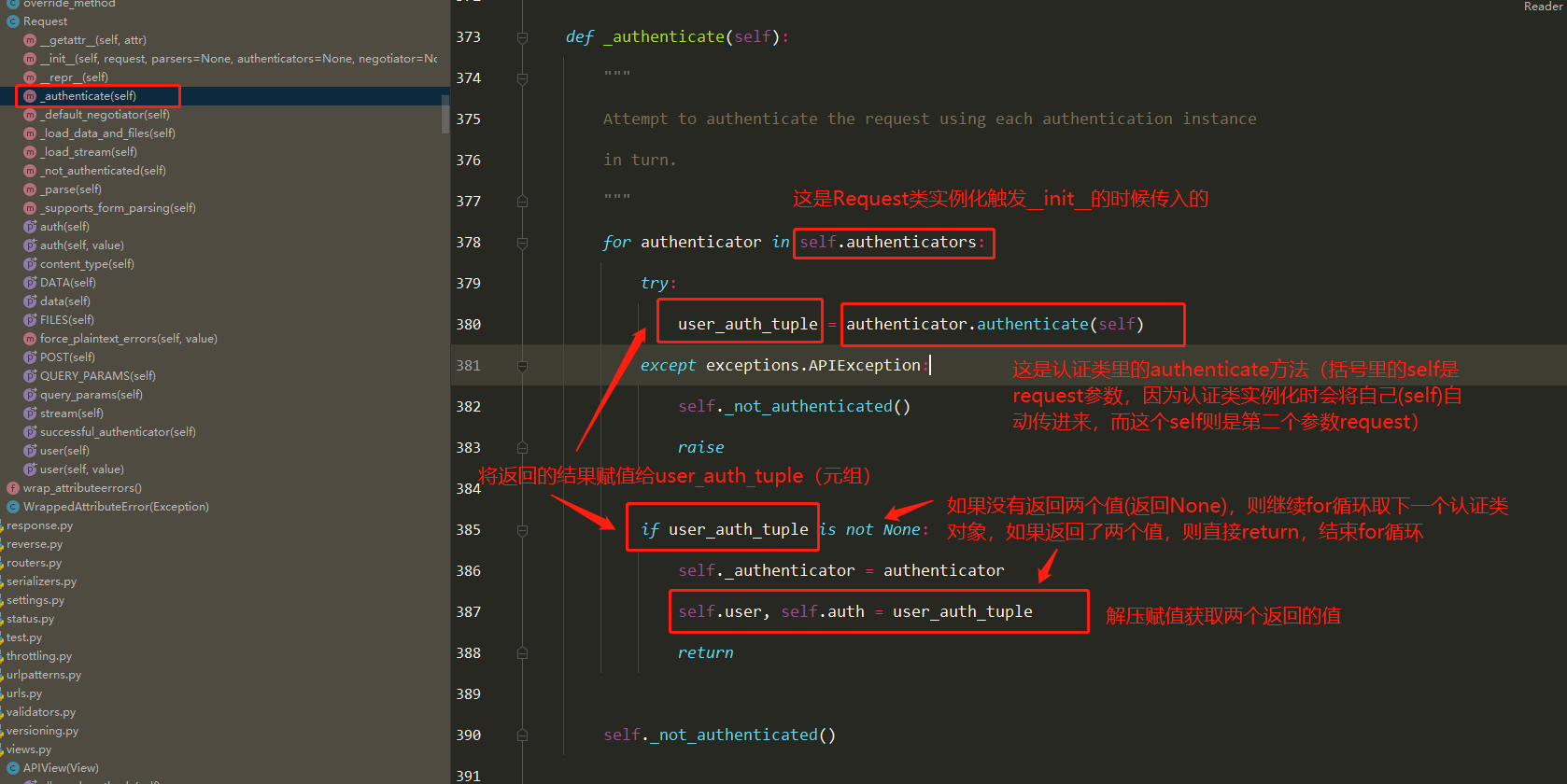
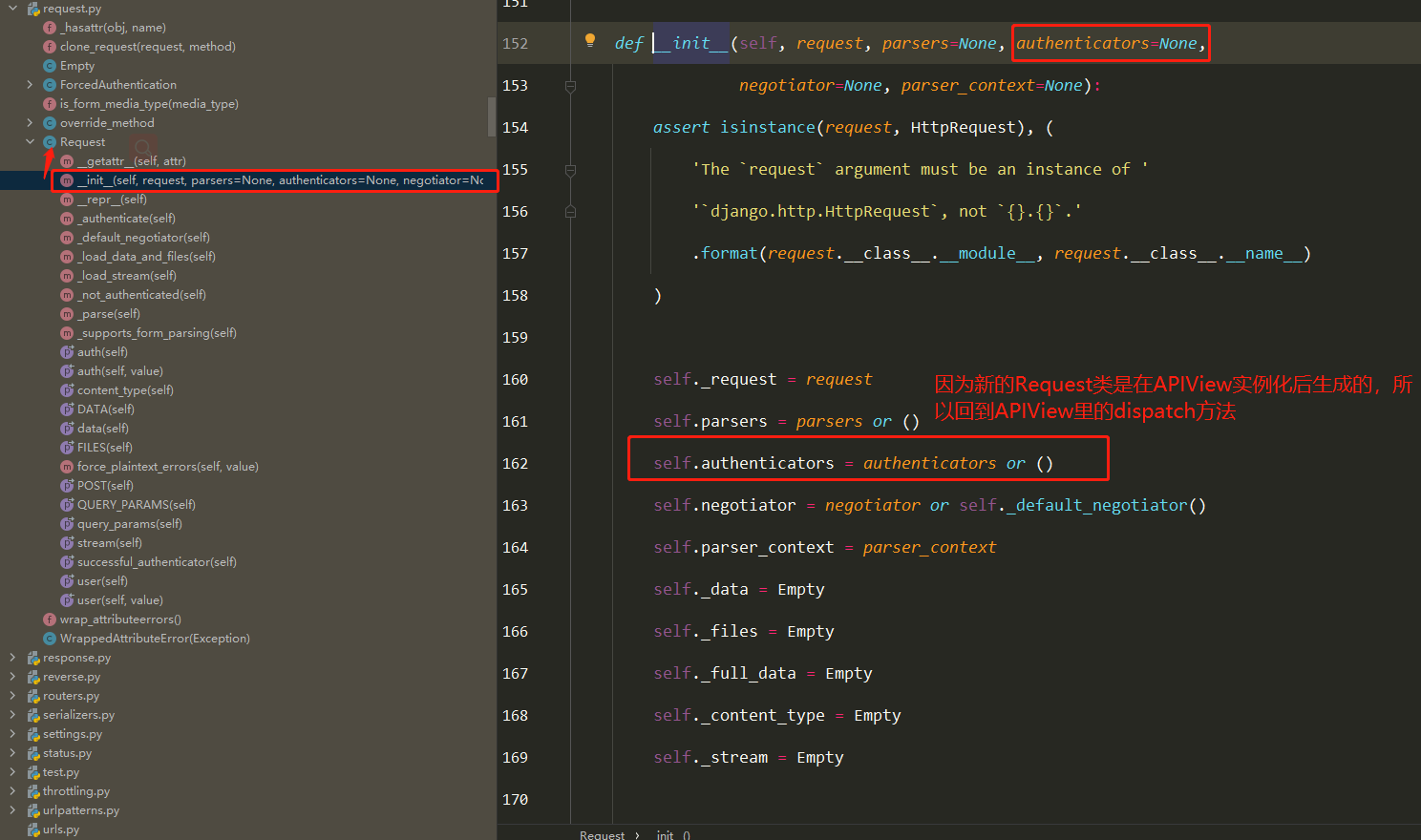
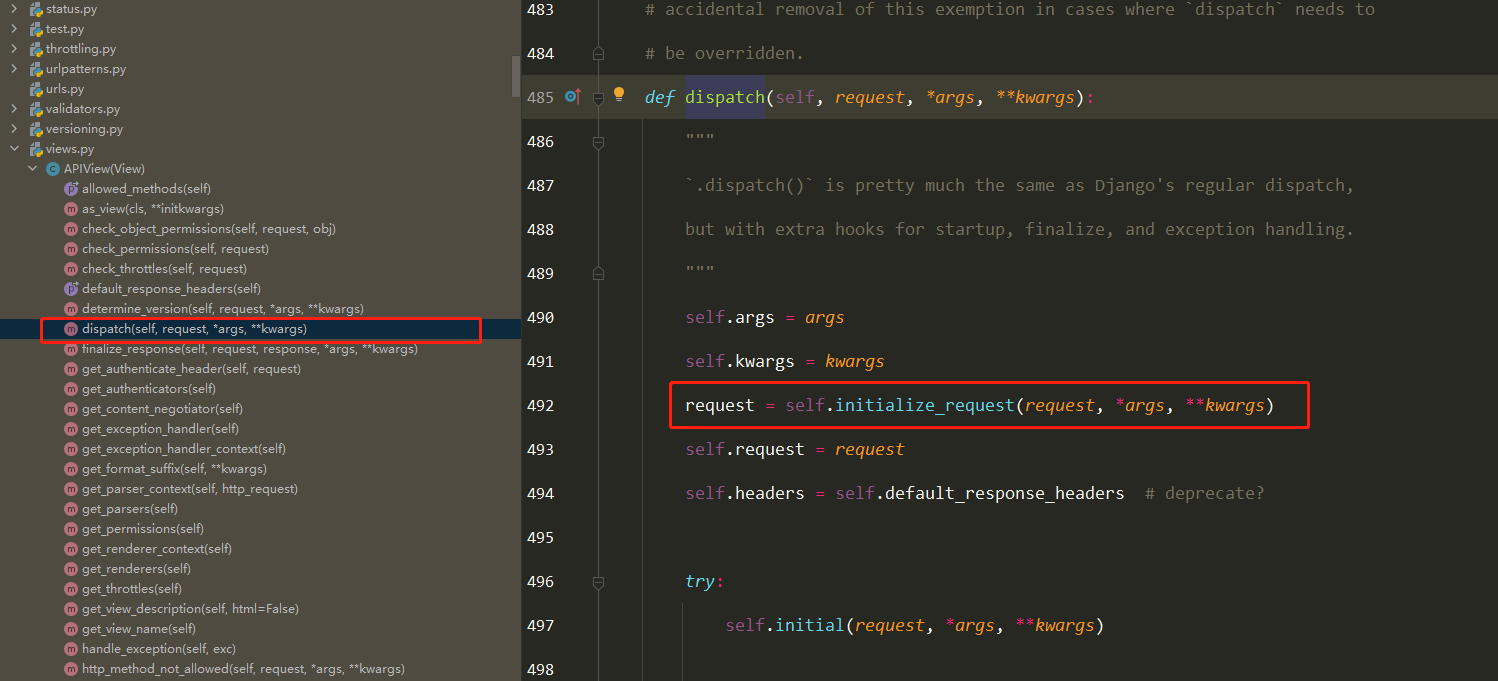
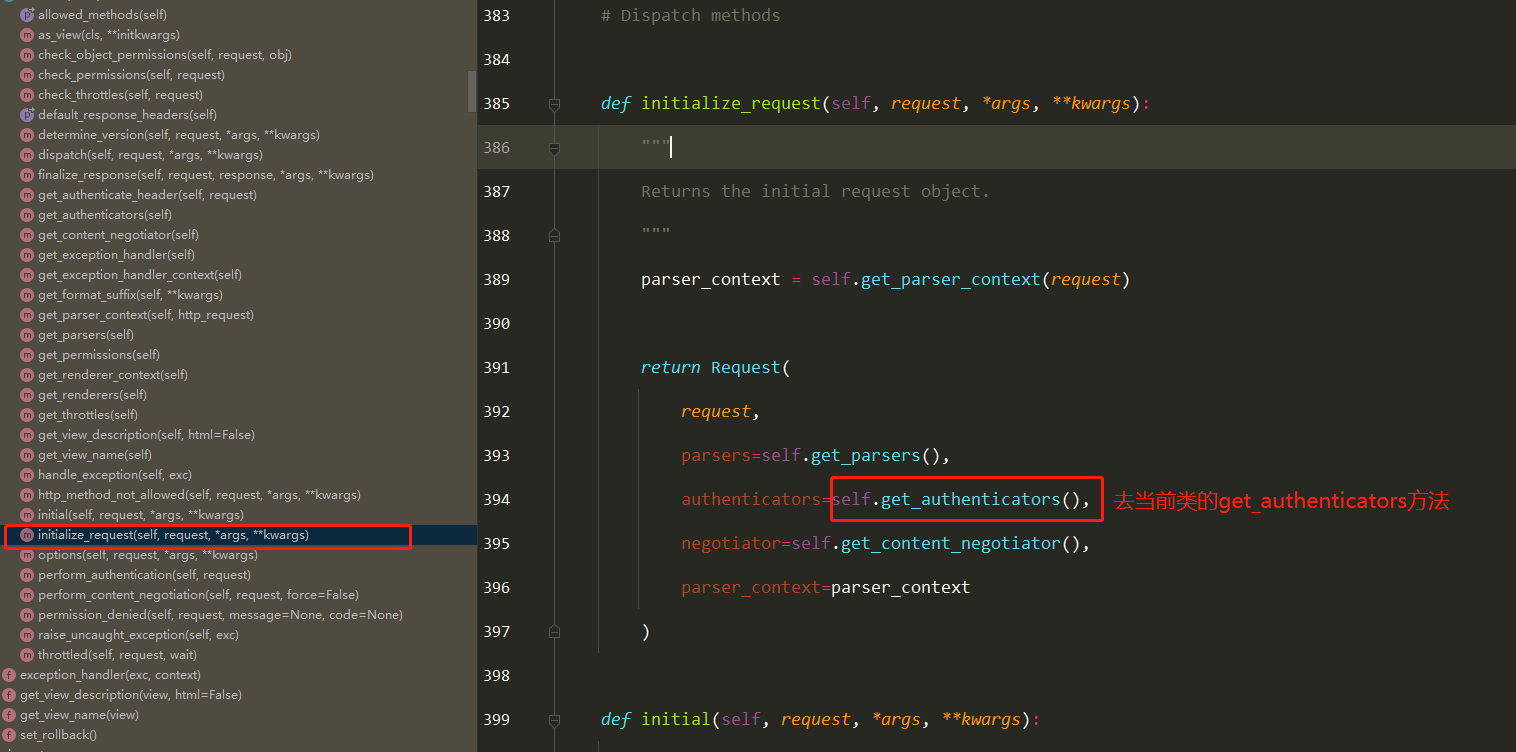
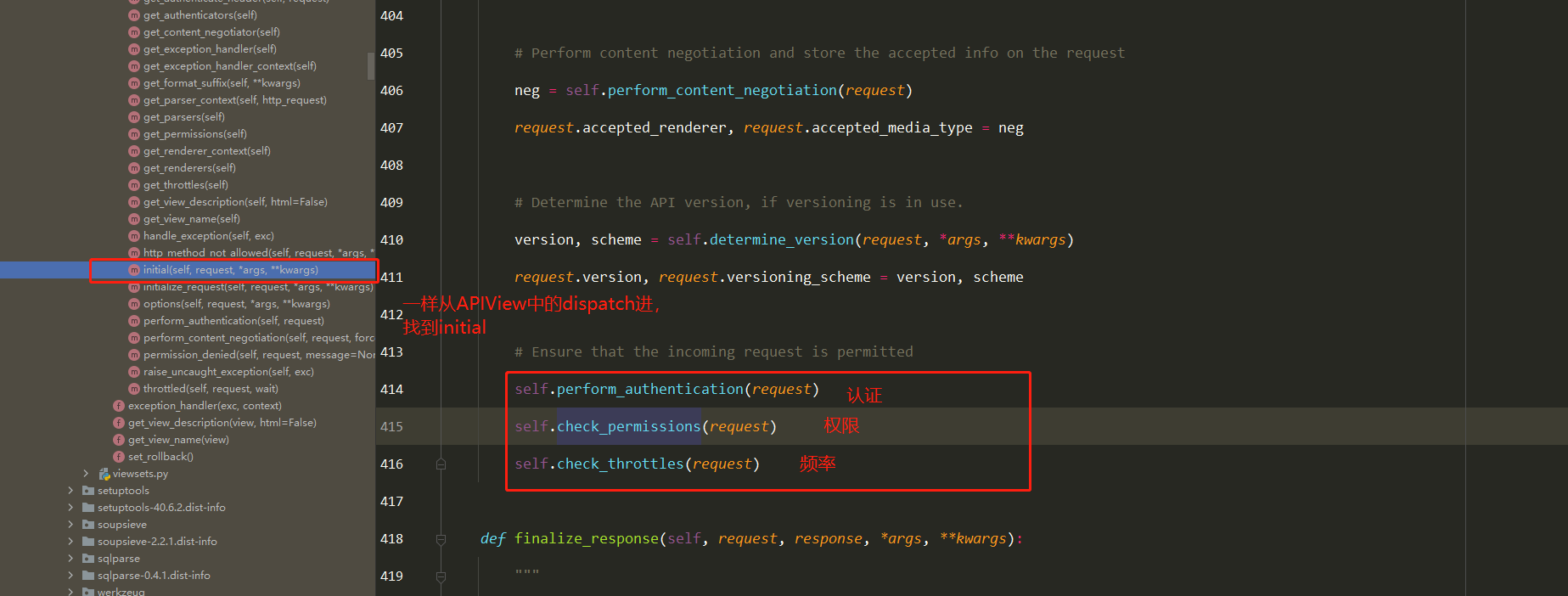
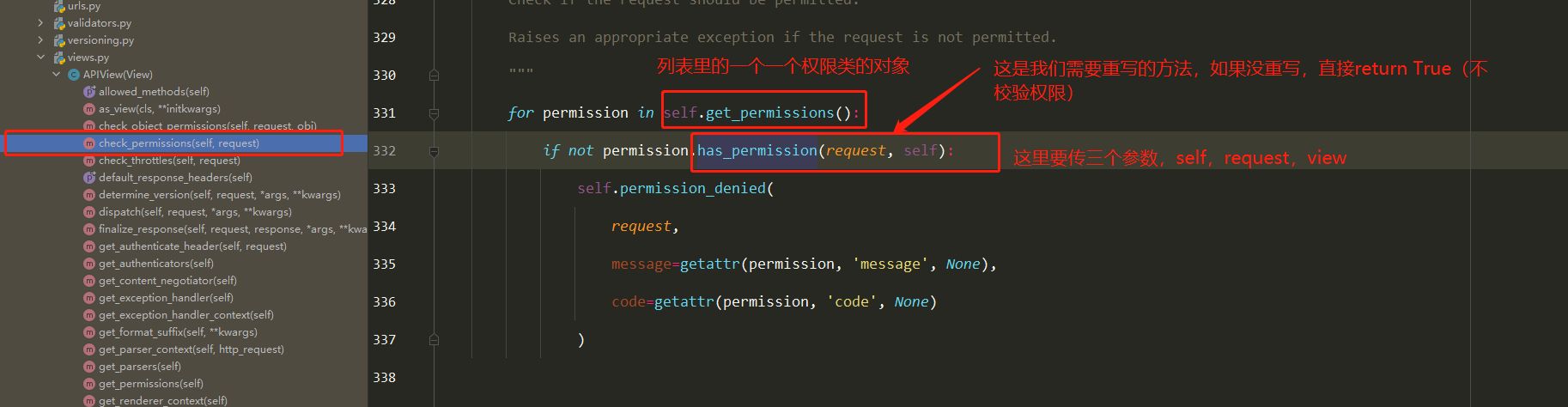
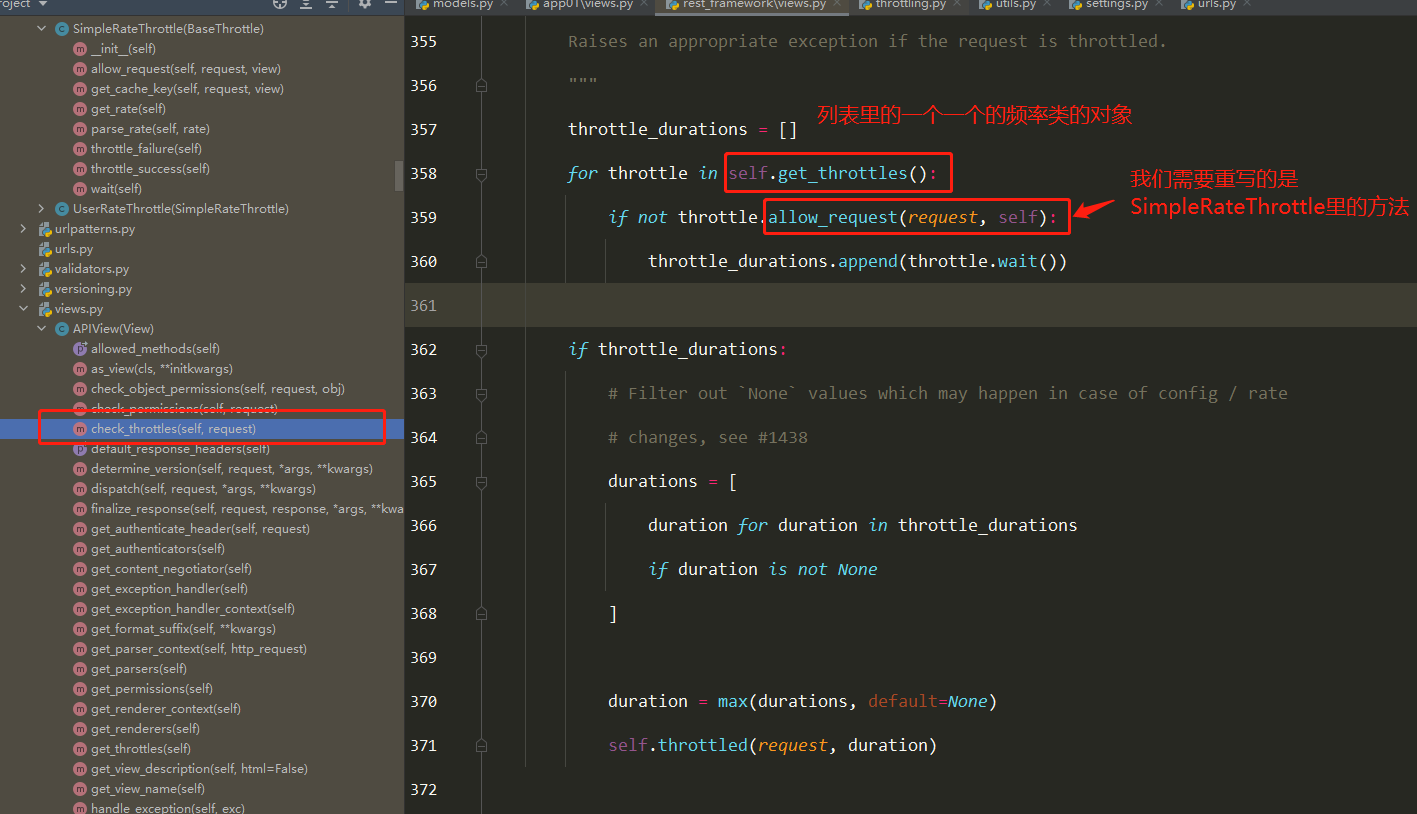
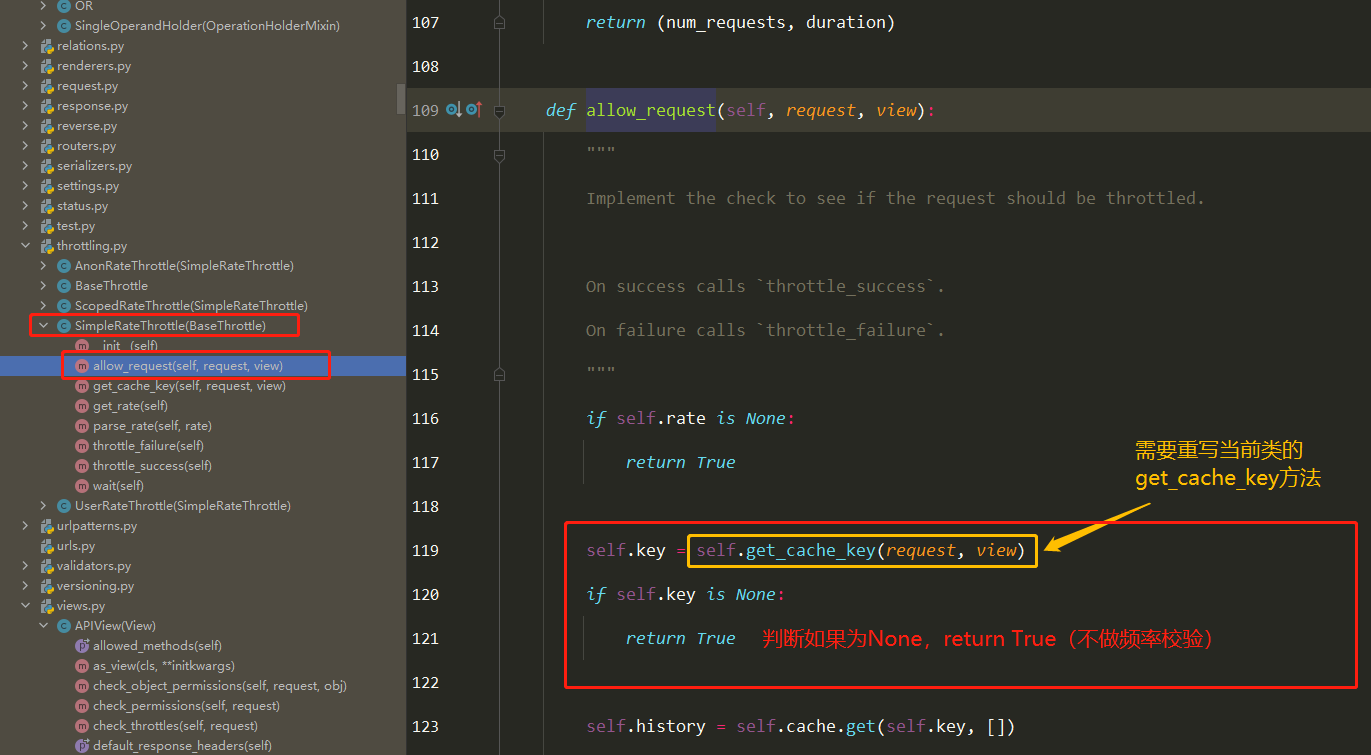
底层原理 Docker是怎么工作的?
Docker是一个C/S结构的系统,Docker的守护进程运行在主机上.通过Socket从客户端访问!
DockerServer接收到Docker-Client的指令,就会执行这个命令!
Docker为什么比VM快?
Docker有着比虚拟机更少的抽象层
Docker利用的是宿主机的内核,vm需要的是Guest OS
所以说,新建一个容器的时候,docker不需要像虚拟机一样重新安装一个操作系统内核,虚拟机是加载Guest OS,分钟级别的,而docker是利用宿主机的操作系统,省略了这个复杂的过程
Docker的常用命令 帮助命令 1 2 3 docker version # docker版本 docker info # 显示docker的系统信息,包括镜像和容器的数量 docker [命令] --help # 查看某个具体的命令
镜像命令 查看下载的所有镜像
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # docker images REPOSITORY TAG IMAGE ID CREATED SIZE mysql 5.6 8de95e6026c3 20 hours ago 302MB redis latest 36304d3b4540 12 days ago 104MB mysql latest 30f937e841c8 2 weeks ago 541MB centos/mysql-57-centos7 latest f83a2938370c 8 months ago 452MB # 解释 REPOSITORY 镜像的仓库名 TAG 镜像的标签 IMAGE ID 镜像ID CREATED 镜像创建时间 SIZE 镜像的大小 # 可选项 Options: -a, --all # 列出所有镜像 -q, --quiet # 只显示镜像ID
搜索镜像
1 2 3 4 5 6 7 8 # docker search [root@CZP ~]# docker search mysql NAME DESCRIPTION STARS OFFICIAL AUTOMATED mysql MySQL is a widely used, open-source relation… 9604 [OK] # 可选项,通过收藏来过滤 --filter=stars=3000 # 搜索出来的镜像收藏就是大于3000的
下载镜像
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # docker pull [root@CZP ~] # docker pull nginx [:tag] Using default tag: latest # 如果不写tag 默认使用最新版本 latest: Pulling from library/nginx 8559a31e96f4: Pull complete # 分层下载,docker image核心 联合文件系统 8d69e59170f7: Pull complete 3f9f1ec1d262: Pull complete d1f5ff4f210d: Pull complete 1e22bfa8652e: Pull complete Digest: sha256:21f32f6c08406306d822a0e6e8b7dc81f53f336570e852e25fbe1e3e3d0d0133 # 签名 Status: Downloaded newer image for nginx:latest docker.io/library/nginx:latest # 真实地址 # docker pull nginx 等价于 dicker pull docker.io/library/nginx:latest # 指定版本下载
删除镜像
1 2 3 4 5 6 # docker rmi # 删除指定的容器 [root@CZP ~]# docker rm -f 8de95e6026c3 # 删除全部的容器 [root@CZP ~]# docker rm -f $(docker -ap)
容器命令 说明 : 有了镜像才可以创建容器,
新建容器并启动
1 2 3 4 5 6 7 8 # docker run [可选参数] image # 参数说明 --name="" 容器名字 用于区分容器 -d 后台方式运行 -it 使用交互方式运行,进入容器查看内容 -p 指定容器的端口 -p 80:8080 主机端口:容器端口 -P(大写) 随机指定容器的端口
列出所有运行的容器
1 2 3 4 5 6 7 8 9 10 11 12 # docker ps 命令 (不加参数)列出当前正在运行的容器 # 参数说明 -a # 列出当前正在运行的容器+历史运行过的容器 -n=? # 显示最近创建的容器 -q # 只显示容器的编号 [root@CZP ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES [root@CZP ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 919e58ff5521 redis "docker-entrypoint.s…" 20 hours ago Exited (0) 16 hours ago redis
退出容器
1 2 exit # 直接容器停止并退出 ctrl + p + q # 直接退出容器
删除容器
1 2 3 docker rm 容器id # 删除指定容器(可一次删除多个,各id之间用空格隔开) docker rm -f[递归] $(docker ps -aq) # 递归删除所有的容器 docker ps -a | xargs docker rm # 递归删除所有的容器
启动和停止容器的操作
1 2 3 4 docker start 容器id # 启动容器 docker restart 容器id # 重启容器 docker stop 容器id # 停止当前正在运行的容器 docker kill 容器id # 强制停止当前容器
常用的其他命令 后台启动容器
1 2 3 4 # 命令docker run -d 镜像名 # 常见的坑: docker容器后台运行,就必须要有一个前台进程,docker发现没有应用,就会自动停止 # nginx, 容器启动后,发现自己没有提供服务,就会立刻停止,就是没有程序了
查看日志
1 2 3 4 5 6 7 8 9 10 11 12 docker logs -f -t --tail 容器 -tf --tail number [root@localhost ~] 2021-06-26T01:38:12.739000465Z [root@ef24fc0af36a /] 2021-06-26T01:38:12.739180686Z bash: docker: command not found 2021-06-26T01:38:21.504914487Z [root@ef24fc0af36a /] 2021-06-26T01:38:21.504931415Z exit
查看容器中进程信息
1 2 3 4 5 docker top 容器id [root@CZP ~]# docker top 63d4c4115212 UID PID PPID C STIME polkitd 2319 2301 0 12:33
查看镜像元数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 # 命令 docker inspect 容器id # 测试 [root@CZP ~]# docker inspect 63d4c4115212 [ { "Id": "63d4c41152126cae276b69e1100520f9d6d867f950e488b5488de68181b7870b", "Created": "2020-06-10T04:33:13.666827714Z", "Path": "docker-entrypoint.sh", "Args": [ "redis-server" ], "State": { "Status": "running", "Running": true, "Paused": false, "Restarting": false, "OOMKilled": false, "Dead": false, "Pid": 2319, "ExitCode": 0, "Error": "", "StartedAt": "2020-06-10T04:33:14.008260846Z", "FinishedAt": "0001-01-01T00:00:00Z" }, "Image": "sha256:36304d3b4540c5143673b2cefaba583a0426b57c709b5a35363f96a3510058cd", "ResolvConfPath": "/var/lib/docker/containers/63d4c41152126cae276b69e1100520f9d6d867f950e488b5488de68181b7870b/resolv.conf", "HostnamePath": "/var/lib/docker/containers/63d4c41152126cae276b69e1100520f9d6d867f950e488b5488de68181b7870b/hostname", "HostsPath": "/var/lib/docker/containers/63d4c41152126cae276b69e1100520f9d6d867f950e488b5488de68181b7870b/hosts", "LogPath": "/var/lib/docker/containers/63d4c41152126cae276b69e1100520f9d6d867f950e488b5488de68181b7870b/63d4c41152126cae276b69e1100520f9d6d867f950e488b5488de68181b7870b-json.log", "Name": "/redis", "RestartCount": 0, "Driver": "overlay2", "Platform": "linux", "MountLabel": "", "ProcessLabel": "", "AppArmorProfile": "", "ExecIDs": null, "HostConfig": { "Binds": null, "ContainerIDFile": "", "LogConfig": { "Type": "json-file", "Config": {} }, "NetworkMode": "default", "PortBindings": { "6379/tcp": [ { "HostIp": "", "HostPort": "6379" } ] }, "RestartPolicy": { "Name": "no", "MaximumRetryCount": 0 }, "AutoRemove": false, "VolumeDriver": "", "VolumesFrom": null, "CapAdd": null, "CapDrop": null, "Capabilities": null, "Dns": [], "DnsOptions": [], "DnsSearch": [], "ExtraHosts": null, "GroupAdd": null, "IpcMode": "private", "Cgroup": "", "Links": null, "OomScoreAdj": 0, "PidMode": "", "Privileged": false, "PublishAllPorts": false, "ReadonlyRootfs": false, "SecurityOpt": null, "UTSMode": "", "UsernsMode": "", "ShmSize": 67108864, "Runtime": "runc", "ConsoleSize": [ 0, 0 ], "Isolation": "", "CpuShares": 0, "Memory": 0, "NanoCpus": 0, "CgroupParent": "", "BlkioWeight": 0, "BlkioWeightDevice": [], "BlkioDeviceReadBps": null, "BlkioDeviceWriteBps": null, "BlkioDeviceReadIOps": null, "BlkioDeviceWriteIOps": null, "CpuPeriod": 0, "CpuQuota": 0, "CpuRealtimePeriod": 0, "CpuRealtimeRuntime": 0, "CpusetCpus": "", "CpusetMems": "", "Devices": [], "DeviceCgroupRules": null, "DeviceRequests": null, "KernelMemory": 0, "KernelMemoryTCP": 0, "MemoryReservation": 0, "MemorySwap": 0, "MemorySwappiness": null, "OomKillDisable": false, "PidsLimit": null, "Ulimits": null, "CpuCount": 0, "CpuPercent": 0, "IOMaximumIOps": 0, "IOMaximumBandwidth": 0, "MaskedPaths": [ "/proc/asound", "/proc/acpi", "/proc/kcore", "/proc/keys", "/proc/latency_stats", "/proc/timer_list", "/proc/timer_stats", "/proc/sched_debug", "/proc/scsi", "/sys/firmware" ], "ReadonlyPaths": [ "/proc/bus", "/proc/fs", "/proc/irq", "/proc/sys", "/proc/sysrq-trigger" ] }, "GraphDriver": { "Data": { "LowerDir": "/var/lib/docker/overlay2/db63749d3abd5e587a88360e27fc9b5b0db7069b45e2bd8c48c75e25eba89100-init/diff:/var/lib/docker/overlay2/30d298e0d46edd68a8cbb588247384b9516d1140f5ca592b7f0b1c04618111f0/diff:/var/lib/docker/overlay2/af6963cd652870740eec10549b2a6c8f08b94edb3a3cea1a42d727026bb6d5a0/diff:/var/lib/docker/overlay2/af514c78199cdcfb30194921b892782dacbe1a3f439167f2f434b2f5a55ab5c3/diff:/var/lib/docker/overlay2/b1e020f1a03a66483794af0cf20d59e8dfa471f692ecaa145398d30500370a2a/diff:/var/lib/docker/overlay2/e55685d1f4ea504c3df5c3cbe822ab000f6412d3eff50b6b8ba097fb551ad922/diff:/var/lib/docker/overlay2/df78a0d3f0dbc449650ce5605d67ff45e93dbadc4fe93d2b7552203a31ab46a8/diff", "MergedDir": "/var/lib/docker/overlay2/db63749d3abd5e587a88360e27fc9b5b0db7069b45e2bd8c48c75e25eba89100/merged", "UpperDir": "/var/lib/docker/overlay2/db63749d3abd5e587a88360e27fc9b5b0db7069b45e2bd8c48c75e25eba89100/diff", "WorkDir": "/var/lib/docker/overlay2/db63749d3abd5e587a88360e27fc9b5b0db7069b45e2bd8c48c75e25eba89100/work" }, "Name": "overlay2" }, "Mounts": [ { "Type": "volume", "Name": "f544b94e9e0129e7f438b851edbfc94a82c96e6fdda44179d38e20f800878a6a", "Source": "/var/lib/docker/volumes/f544b94e9e0129e7f438b851edbfc94a82c96e6fdda44179d38e20f800878a6a/_data", "Destination": "/data", "Driver": "local", "Mode": "", "RW": true, "Propagation": "" } ], "Config": { "Hostname": "63d4c4115212", "Domainname": "", "User": "", "AttachStdin": false, "AttachStdout": false, "AttachStderr": false, "ExposedPorts": { "6379/tcp": {} }, "Tty": false, "OpenStdin": false, "StdinOnce": false, "Env": [ "PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin", "GOSU_VERSION=1.12", "REDIS_VERSION=6.0.4", "REDIS_DOWNLOAD_URL=http://download.redis.io/releases/redis-6.0.4.tar.gz", "REDIS_DOWNLOAD_SHA=3337005a1e0c3aa293c87c313467ea8ac11984921fab08807998ba765c9943de" ], "Cmd": [ "redis-server" ], "Image": "36304d3b4540", "Volumes": { "/data": {} }, "WorkingDir": "/data", "Entrypoint": [ "docker-entrypoint.sh" ], "OnBuild": null, "Labels": {} }, "NetworkSettings": { "Bridge": "", "SandboxID": "5f8321169dfd067e45f2921d73984d0d76e953cd642d93990d1ed8a3227ad53f", "HairpinMode": false, "LinkLocalIPv6Address": "", "LinkLocalIPv6PrefixLen": 0, "Ports": { "6379/tcp": [ { "HostIp": "0.0.0.0", "HostPort": "6379" } ] }, "SandboxKey": "/var/run/docker/netns/5f8321169dfd", "SecondaryIPAddresses": null, "SecondaryIPv6Addresses": null, "EndpointID": "33eafd9f86d5e7a3b29ed09fe75d8eb27e0227a07607960550dfef7f620a6872", "Gateway": "172.18.0.1", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "IPAddress": "172.18.0.2", "IPPrefixLen": 16, "IPv6Gateway": "", "MacAddress": "02:42:ac:12:00:02", "Networks": { "bridge": { "IPAMConfig": null, "Links": null, "Aliases": null, "NetworkID": "228826a97a0b066a01811c098e4c4985804598571b9c8d9ad4205a0ee75c8b5b", "EndpointID": "33eafd9f86d5e7a3b29ed09fe75d8eb27e0227a07607960550dfef7f620a6872", "Gateway": "172.18.0.1", "IPAddress": "172.18.0.2", "IPPrefixLen": 16, "IPv6Gateway": "", "GlobalIPv6Address": "", "GlobalIPv6PrefixLen": 0, "MacAddress": "02:42:ac:12:00:02", "DriverOpts": null } } } }
进入当前正在运行的容器
1 2 3 4 5 6 7 8 # 我们通常容器都是使用后台方式运行的,需要进入容器,修改一些配置 # 命令 docker exec -it 容器id bashshell 默认命令行 docker attach 容器id # docker exec # docker attach
从容器内拷贝文件到主机上
1 docker cp 容器id:容器内路径 目的主机路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 attach Attach to a running container build Build an image from a Dockerfile commit Create a new image from a container's changes # 提交当前容器为新的镜像 cp Copy files/folders between a container and the local filesystem # 从容器中拷贝指定的文件或者目录到宿主机上 create Create a new container # 创建一个新的容器,同run 但不启动容器 diff Inspect changeson a container' s filesystem events Get real time events from the server exec Run a command in a running container export Export a container's filesystem as a tar archive # 导出容器的内容流作为一个tar归档文件[对应import] history Show the history of an image # 展示一个镜像形成历史 images List images # 列出系统当前镜像 import Import the contents from a tarball to create a filesystem image # 从tar包中的内容创建一个新的文件系统映像[对应export] info Display system-wide information # 显示系统相关信息 inspect Return low-level information on Docker objects # 查看容器详细信息 kill Kill one or more running containers # kill指定docker容器 load Load an image from a tar archive or STDIN # 从一个tar包加载一个镜像[对应save] login Log in to a Docker registry # 注册或者登录一个docker源服务器 logout Log out from a Docker registry # 从当前docker registry退出 logs Fetch the logs of a container # 输出当前容器日志信息 pause Pause all processes within one or more containers # 暂停容器 port List port mappings or a specific mapping for the container # 查看映射端口对应的容器内部源端口 ps List containers # 列出容器列表 pull Pull an image or a repository from a registry # 从docker镜像源服务器拉取指定镜像或库镜像 push Push an image or a repository to a registry # 推送指定镜像或库镜像至docker源服务器 rename Rename a container # 重命名容器 restart Restart one or more containers # 重启运行的容器 rm Remove one or more containers # 移除一个或多个容器 rmi Remove one or more images # 移除一个或多个镜像(没有容器使用当前镜像才可删除,否则需要删除相关容器或者使用-f参数强制删除) run Run a command in a new container # 创建一个新的容器并运行一个命令 save Save one or more images to a tar archive (streamed to STDOUT by default) # 保存一个镜像为一个tar包[对应load] search Search the Docker Hub for images # 在docker hub中搜索镜像 start Start one or more stopped containers # 启动容器 stats Display a live stream of container(s) resource usage statistics # 查看cpu的状态 stop Stop one or more running containers # 停止容器 tag Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE # 给源中镜像打标签 top Display the running processes of a container # 查看容器中运行的进程信息 unpause Unpause all processes within one or more containers # 取消暂停容器 update Update configuration of one or more containers # 更新一个或多个容器的配置 version Show the Docker version information # 查看docker版本号 wait Block until one or more containers stop, then print their exit codes # 截取容器停止时的退出状态值
Docker 安装Nginx
1 2 3 4 5 6 7 8 9 10 11 12 13 # 1. 搜索镜像 search 建议大家去docker搜索,可以看到帮助文档 # 2. 拉取镜像 pull # 3、运行测试 # -d 后台运行 # --name 给容器命名 # -p 宿主机端口:容器内部端口 ➜ ~ docker run -d --name nginx00 -p 82:80 nginx 75943663c116f5ed006a0042c42f78e9a1a6a52eba66311666eee12e1c8a4502 ➜ ~ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 75943663c116 nginx "nginx -g 'daemon of…" 41 seconds ago Up 40 seconds 0.0.0.0:82->80/tcp nginx00 ➜ ~ curl localhost:82 #测试 <!DOCTYPE html>,,,,
思考问题:我们每次改动nginx配置文件,都需要进入容器内部?十分的麻烦,要是可以在容器外部提供一个映射路径,达到在容器修改文件名,容器内部就可以自动修改数据卷!
作业:docker 来装一个tomcat
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 官方的使用 docker run -it --rm tomcat:9.0 # 之前的启动都是后台,停止了容器,容器还是可以查到, docker run -it --rm image 一般是用来测试,用完就删除 --rm Automatically remove the container when it exits # 下载 docker pull tomcat # 启动运行 docker run -d -p 8080:8080 --name tomcat01 tomcat # 测试访问有没有问题 curl localhost:8080 # 进入容器 ➜ ~ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES db09851cf82e tomcat "catalina.sh run" 28 seconds ago Up 27 seconds 0.0.0.0:8080->8080/tcp tomcat01 ➜ ~ docker exec -it db09851cf82e /bin/bash root@db09851cf82e:/usr/local/tomcat# # 发现问题:1、linux命令少了。 2.没有webapps
思考问题:我们以后要部署项目,如果每次都要进入容器是不是十分麻烦?要是可以在容器外部提供一个映射路径,webapps,我们在外部放置项目,就自动同步内部就好了!
作业:部署es+kibana
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 # es 暴露的端口很多! # es 的数据一般需要放置到安全目录!挂载 # --net somenetwork ? 网络配置 # 启动elasticsearch docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.6.2 # 测试一下es是否成功启动 ➜ ~ curl localhost:9200 { "name" : "d73ad2f22dd3", "cluster_name" : "docker-cluster", "cluster_uuid" : "atFKgANxS8CzgIyCB8PGxA", "version" : { "number" : "7.6.2", "build_flavor" : "default", "build_type" : "docker", "build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f", "build_date" : "2020-03-26T06:34:37.794943Z", "build_snapshot" : false, "lucene_version" : "8.4.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" } ➜ ~ docker stats # 查看docker容器使用内存情况 CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS bd4094db247f elasticsearch 1.57% 1.226GiB / 3.7GiB 33.13% 0B / 0B 0B / 0B 42 94b00b6f6172 tomcat 0.18% 78.58MiB / 3.7GiB 2.07% 1.69kB / 2.47kB 0B / 0B 37 d458bc50a808 nginx01 0.00% 1.883MiB / 3.7GiB 0.05% 5.22kB / 6.32kB 0B / 0B 3 63d4c4115212 redis 0.14% 9.637MiB / 3.7GiB 0.25% 10.8kB / 14.2kB 0B / 0B 7
1 2 3 # elasticsearch十分占用内存,需要修改配置文件 -e 限制其启动的内存 docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e ES_JAVA_OPTS= "-Xms64m -Xmx 512m" elasticsearch:7.6.2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@CZP ~]# curl localhost:9200 { "name" : "bd4094db247f", "cluster_name" : "docker-cluster", "cluster_uuid" : "U3TfPp1rQ6uitn0WMh6pRQ", "version" : { "number" : "7.6.2", "build_flavor" : "default", "build_type" : "docker", "build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f", "build_date" : "2020-03-26T06:34:37.794943Z", "build_snapshot" : false, "lucene_version" : "8.4.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }
docker和kibana如何连接
可视化
1 2 docker run -d -p 8080:9000 \ --restart=always -v /var/run/docker.sock:/var/run/docker.sock --privileged=true portainer/portainer
什么是portainer?
Docker图形化界面管理工具! 提供一个后台面板供我们操作
1 2 docker run -d -p 8080:9000 \ --restart=always -v /var/run/docker.sock:/var/run/docker.sock --privileged=true portainer/portainer
访问测试: 外网: 8088 http://外网ip:8088/
进入之后的面板
Docker镜像讲解 镜像是什么 镜像就是一个轻量级的,可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码,运行时,库,环境变量和配置文件。
所有的应用,直接打包docker镜像,就可以直接跑起来!
如何得到镜像:
从远程仓库下载
朋友拷贝给你
自己制作一个镜像 DockerFile
Docker镜像加载原理
UnionFs(联合文件系统查询)
我们下载的时候看到的一层一层就是这个
UnionFs(联合文件系统): Union文件系统(UnionFS)是一种分层,轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下,Union文件系统是Docker镜像的基础,镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像
特性: 一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录结构
Docker镜像加载原理
docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统UnionFS
bootfs(boot file system)主要包含bootlloader和kernel,bootfs主要是引导加载kernel,Linux刚启动时会加载bootfs文件系统,在docker镜像的最底层是bootfs,这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核,当boot加载完成之后整个内核就在内存中了,此时内存的使用权已由bootfa转交给内核,此时系统也会卸载bootfs
rootfs(root file system),在bootfs之上,包含的就是典型Linux系统中的/dev, /proc,/bin, /etc等标准目录和文件,rootfs就是各种不同的操作系统发行版,比如Ubuntu, CentOS等等
平时我们安装进虚拟机的CentOS都是好几个G,为什么Docker这里才200M?
对于一个精简的OS,rootfs可以很小,只需要包含基本的命令,工具和程序库就可以了,因为底层直接用Host的kernel,自己只需要提供rootFS就可以了。由此可见对于不同的linux发行版,bootfs基本是一致的,rootfs会有差别,因此不同的发行版可以共用bootfs
分层理解
分层的镜像
我们可以去下载一个镜像,注意观察下载的日志输出,可以看到是一层一层的在下载!
思考: 为什么Docker镜像要采用这种分层的结构呢?
最大好处,我觉得莫过于资源共享了!比如有多个镜像都从相同的Base镜像构建而来,那么宿主机
只需在磁盘上保留一份base镜像,同时内存中也只需要加载一份base镜像,这样就可以为所有的容器服务了,而且镜像的每一层都可以被共享
查看镜像分层的方式可以通过 docker image inspect 命令!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@CZP ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE nginx latest 2622e6cca7eb 32 hours ago 132MB portainer/portainer latest cd645f5a4769 9 days ago 79.1MB redis latest 36304d3b4540 13 days ago 104MB mysql latest 30f937e841c8 2 weeks ago 541MB tomcat 9.0 1b6b1fe7261e 3 weeks ago 647MB elasticsearch 7.6.2 f29a1ee41030 2 months ago 791MB elasticsearch latest 5acf0e8da90b 20 months ago 486MB [root@CZP ~]# docker image inspect redis [ "RootFS": { "Type": "layers", "Layers": [ "sha256:ffc9b21953f4cd7956cdf532a5db04ff0a2daa7475ad796f1bad58cfbaf77a07", "sha256:d4e681f320297add0ede0554524eb9106d8c3eb3a43e6e99d79db6f76f020248", "sha256:59bd5a888296b623ae5a9efc8f18285c8ac1a8662e5d3775a0d2d736c66ba825", "sha256:c112794a20c5eda6a791cbec8700fb98eab30671a2248ac7e2059b475c46c45f", "sha256:bf8b736583f08c02b92f8a75ac5ea181e4d74107876177caa80ddad8b6b57a72", "sha256:6ef422d19214800243b28017d346c7ab9bfe63cb198a39312d1714394b232449" ] } ]
理解:
所有的镜像都起始于一个基础镜像层,当进行修改或增加新的内容时,就会在当前镜像层之上,创建一个新的镜像层,
举一个简单的例子,假如基于Ubuntu Linux 16.64创建一个新的镜像,这就是新镜像的第一层,如果在该镜像中添加python包,就会在该镜像之上创建第二个镜像层; 如果继续添加一个安全补丁,就会创建第三个镜像层
该镜像已经包含3个镜像层,如下图所示(这只是一个简单的例子)
上图中的镜像层跟之前图中的略有区别,主要是便于展示文件
下图中展示了一个稍微复杂的三层镜像,在外部看来整个镜像只有6个文件,这是因为最上层的文件7是文件5的一个更新版本
这种情况下,上层镜像层中的文件覆盖了底层镜像层中的文件,这样就使得文件的更新版本作为一个新镜像层添加到镜像当中
Docker通过存储引擎(新版本采用快照机制)的方式来实现镜像层堆栈,并保证多层镜像层对外展示为统一的文件系统
Lunux上可用的存储引擎有AUFS,Overlay2,Device Mapper,Btrfs以及ZFS,顾名思义,每种存储引擎都是基于Linux对应的文件系统或者块设备技术,并且每种存储引擎都有其独有的性能特点
Docker在Windows上仅支持windosfilter一种存储引擎,该引擎基于NTFS文件系统之上实现了分层和CoW[1]
下图展示了与系统显示相同的三层镜像,所有的镜像层堆叠合并,对外提供统一的视图层
特点
Docker镜像都是只读的,当容器启动时,一个新的可写层被加载到镜像的顶部!
这一层就是我们通常所说的容器层,容器之下的都叫镜像层
如何提交一个自己的镜像
commit镜像 1 2 3 4 docker commit 提交容器成为一个新的镜像 # 命令和git原理类似 docker commit -m="提交的描述信息" -a="作者" 容器ID 目标镜像名:[tag]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@CZP ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES db186da947d7 portainer/portainer "/portainer" 16 hours ago Up 16 hours 0.0.0.0:8088->9000/tcp interesting_shockley bd4094db247f elasticsearch:7.6.2 "/usr/local/bin/dock…" 17 hours ago Up 17 hours 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch 94b00b6f6172 tomcat:9.0 "catalina.sh run" 17 hours ago Up 17 hours 0.0.0.0:8080->8080/tcp tomcat d458bc50a808 nginx "/docker-entrypoint.…" 18 hours ago Up 18 hours 0.0.0.0:80->80/tcp nginx01 63d4c4115212 36304d3b4540 "docker-entrypoint.s…" 22 hours ago Up 22 hours 0.0.0.0:6379->6379/tcp redis [root@CZP ~]# docker commit -a="czp" -m="add basic webapps app" 94b00b6f6172 tomcat_9.0:1.0 sha256:75e6ea173695b146c9ddf9d5865e7bdeb78e69c84d2d3520e516cd9f498a1e9a [root@CZP ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE tomcat_9.0 1.0 75e6ea173695 8 seconds ago 652MB nginx latest 2622e6cca7eb 33 hours ago 132MB portainer/portainer latest cd645f5a4769 9 days ago 79.1MB redis latest 36304d3b4540 13 days ago 104MB mysql latest 30f937e841c8 2 weeks ago 541MB tomcat 9.0 1b6b1fe7261e 3 weeks ago 647MB elasticsearch 7.6.2 f29a1ee41030 2 months ago 791MB elasticsearch latest 5acf0e8da90b 20 months ago 486MB
容器数据卷 什么是容器数据卷 docker的理念回顾
将应用和环境打包成一个镜像!
如果数据都在容器中,那么我们容器删除,数据就会丢失! ==需求: 数据可以持久化==
MYSQL, 容器删了,删库跑路! ==需求: mysql数据可以存储在本地!==
容器之间可以有一个数据共享的技术! Docker 容器中产生的数据,同步到本地!
这就是卷技术! 目录的挂载,将容器内的目录挂载到Linux上面!
总结一句话: 容器的持久化和同步操作! 容器间也可以数据共享的!
使用数据卷
方式一: 直接使用命令来挂载 -v
1 2 3 docker run -it -v 主机目录: 容器内目录 -p 主机端口: 容器端口 # 启动起来我们可以使用 docker inspect 容器id
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 将宿主机的/root/test 挂载到tomcat的/home目录 [root@CZP ~]# docker run -d -p 9999:8080 -v /root/test:/home --name="tomcat01" 1b6b1fe7261e 015001911b67f5e357b93c6bb05ebaf07aebe4f3abc455f9aa439afd83b9af78 [root@CZP ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 015001911b67 1b6b1fe7261e "catalina.sh run" 16 seconds ago Up 15 seconds 0.0.0.0:9999->8080/tcp tomcat01 db186da947d7 portainer/portainer "/portainer" 17 hours ago Up 17 hours 0.0.0.0:8088->9000/tcp interesting_shockley bd4094db247f elasticsearch:7.6.2 "/usr/local/bin/dock…" 18 hours ago Up 17 hours 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch 94b00b6f6172 tomcat:9.0 "catalina.sh run" 18 hours ago Up 18 hours 0.0.0.0:8080->8080/tcp tomcat d458bc50a808 nginx "/docker-entrypoint.…" 18 hours ago Up 18 hours 0.0.0.0:80->80/tcp nginx01 63d4c4115212 36304d3b4540 "docker-entrypoint.s…" 22 hours ago Up 22 hours 0.0.0.0:6379->6379/tcp redis # 进入tomcat内部 [root@CZP test]# docker exec -it tomcat01 /bin/bash root@015001911b67:/usr/local/tomcat# cd /home # 在home目录创建b.java root@015001911b67:/home# touch b.java root@015001911b67:/home# read escape sequence [root@CZP test]# cd /root/test [root@CZP test]# ll total 0 -rw-r--r-- 1 root root 0 Jun 11 11:03 b.java # b.java显示挂载成功
实战: 安装Mysql 思考: mysql的数据持久化的问题, data目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 获取镜像 [root@CZP ~]# docker pull mysql:5.7 # 运行容器,需要做数据挂载! # 官方测试: docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=密码 -d mysql:tag # 启动mysql -d 后台运行 -p 端口映射 -v 端口映射 -e 环境配置 --name 容器名 [root@CZP czp]# docker run -d -p 3306:3306 -v /usr/czp/mysql/conf:/etc/mysql/conf.d -v /home/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=sa --name mysql mysql:5.7 # 启动成功之后,我们在本地使用sqlyog来连接测试一下 # sqlyog-连接到服务器的端口 ---服务器端口和容器端口映射,这个时候我们就可以连接上了
假设我们将容器删除
发现,我们挂载到本地的数据卷依旧没有丢失,这就实现了容器数据持久化功能
具名挂载和匿名挂载 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 匿名挂载 -v 容器内路径! docker -run -P -name nginx01 -v /etc/nginx nginx # 查看所有的卷的情况 [root@CZP data]# docker volume ls local 2c04226b82b31e3cddb80b5fffa17685883ff8c256024525b3a65b07b8281110 # 这里发现,这种就是匿名挂载, 我们在 -v只写了容器内的路径,没有写容器外的路径 # 具名挂载 [root@CZP data]# docker run -d -p 9099:80 -v nginxConfig:/etc/nginx 2622e6cca7eb bd7ebf502166e5569ea3fb5eddaf41f4ff9a70df62b9143861dd702ae8c1cb31 [root@CZP data]# docker volume ls DRIVER VOLUME NAME local nginxConfig # 通过 -v 卷名:容器内路径 # 查看一下这个卷
所有的docker容器内的卷,没有指定目录的情况下都是在/var/lib/docker/volumes/卷名/_data
我们通过具名挂载可以方便的找到一个卷,大多数情况在使用的’具名挂载’
1 2 3 4 # 如何确定是具名挂载还是匿名挂载,还是指定路径挂载 -v 容器内路径 # 匿名挂载 -v 卷名:容器内路径 # 具名挂载 -v 宿主机路径 : 容器内路径 # 指定路径挂载
扩展:
1 2 3 4 5 6 7 8 # 通过 -v 容器内路径: ro rw 改变读写权限 ro read only read and write # 一旦设置了容器权限,容器对挂载出来的内容就有限定了! docker -run -P -name nginx01 -v /etc/nginx:ro nginx docker -run -P -name nginx01 -v /etc/nginx:rw nginx ro : 只要看到ro就说明这个路径只能通过宿主机来改变,容器内部无法操作
初始Dockerfile
Dockerfile就是用来构建Dockerfile镜像的文件! 命令脚本!
1 2 3 4 5 6 7 8 9 # 创建一个dockerfile文件,名字可以随机 建议 dockerfile # 文件中的内容 FROM centos VOLUME ["volume01","volume02"] CMD echo "---end---" CMD /bin/hash
这个卷和外部一定有一个同步的目录
查看一下卷挂载的路径
测试一下刚才的文件是否同步出去了
这种方式我们未来使用的十分多,因为我们通常会构建自己的镜像!
假设构建镜像时没有挂载卷,要手动镜像挂载 -v 卷名: 容器内路径
数据卷容器 两个Mysql同步数据!
1 2 # 测试: 可以删除docker01,查看一下docker02和docker03是否还可以访问这个文件 # 测试依旧可以访问
结论:
容器之间配置信息的传递,数据卷容器的生命周期一直持续到没有人使用为止
但是一旦你持久化到了本地,这个时候,本地的数据是不hi删除的
Dockerfile DockerFile是用来构建docker镜像的文件!命令参数脚本!
构建步骤:
编写一个dockerfile脚本
docker build 构建成为一个镜像
docker run 运行镜像
docker push发布镜像(Docker hub , 阿里云镜像仓库! )
很多官方镜像都是基础包, 很多功能没有,我们通常会自己搭建自己的镜像!
官方可以制作镜像,那么我们也可以!
Dockerfile构建过程 很多指令:
每个保留关键字(指令)都是必须要大写
执行从上到下顺序执行
‘#’ 表示注释
每一个指令都会创建提交一个新的镜像层,并提交 !
dockerfile是面向开发的,我们以后要发布项目,做镜像就需要编写dockerfile文件,这个文件十分简单
Docker镜像 逐渐成为了一个企业交付的标准,必须要掌握 !
步骤: 开发,部署,上线,运维…缺一不可
DockerFIle: 构建文件,定义了一切的步骤 ,源代码
DockerImages: 通过DockerFile构建生成的镜像,最终发布运行的产品,原来是一个jar,war
Docker容器: 容器就是镜像运行起来提供服务的
DockerFile的指令 以前的话我们是使用的别人的,现在我们知道了这些指令后,我们来练习自己写一个镜像!
1 2 3 4 5 6 7 8 9 10 11 12 13 FROM # 基础镜像, 一切从这里开始构建 MANTAINER # 镜像是谁写的, 姓名+邮箱 RUN # 镜像构建的时候需要运行的命令 ADD # 步骤, tomcat镜像,压缩包! 添加内容 WORKDIR # 镜像的工作目录 VOLUME # 挂载的目录 EXPOSE # 暴露端口配置 RUN # 运行 CMD # 指定这个容器启动的时候要运行的命令,只有最后一个会生效,可被替代 ENTRYPOINT # 指定这个容器启动的时候要运行的命令,可以追加命令 ONBUILD # 当构建一个被继承 DockerFile 这个时候就会运行ONBUILD的指令,触发指令 COPY # 类似ADD,将我们文件拷贝到镜像中 ENV # 构建的时候设置环境变量!
实战测试 Docker Hub 中99%镜像都是从centos基础镜像过来的,然后配置需要的软件
创建一个自己的centos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # 1 编写一个DOckerfile的文件 FROM centos MAINTAINER czp<2432688105@qq.com> ENV MYPATH /usr/local WORKDIR $MYPATH RUN yum -y install vim RUN yum -y install net-tools EXPOSE 80 CMD echo $MYPATH CMD echo "---end---" # 2. 通过这个文件构建镜像 # 命令 docker build -f dockerfile文件路径 -t Successfully built 5ebc296aad5a Successfully tagged mycentos:1.0 # 3. 测试运行
增强之后的镜像
我们可以列出本地进程的历史
我们平时拿到一个镜像,可以研究一下它是怎么做的
CMD 和ENTRYPOINT的区别
1 2 CMD # 指定这个容器启动的时候要运行的命令,只有最后一个会生效,可被替代 ENTRYPOINT # 指定这个容器启动的时候要运行的命令,可以追加命令
测试cmd命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 编写 [root@CZP dockerfile]# cat dockerfile-centos-test FROM centos CMD ["ls","-a"] # 构建镜像 [root@CZP dockerfile]# docker build -f dockerfile-centos-test -t centostest . # 想要追加一个命令 -l ls -al docker: Error response from daemon: OCI runtime create failed: container_linux.go:349: starting container process caused "exec: \"-l\": executable file not found in $PATH": unknown. ERRO[0000] error waiting for container: context canceled # cmd的情况下 替换了CMD["ls" ,"-a" ]命令,-不是命令追加
ENTRYPOINT是往命令之后追加
实战:Tomcat镜像
准备镜像文件. tomcat压缩包, jdk压缩包!
编写Dockerfile文件, 官方命名 Dockerfile, build会自动寻找这个文件,就不需要 -f 指定了!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 FROM centos MAINTAINER czp<2432688105@qq.com> COPY readme.txt /usr/local/readme.txt ADD apache-tomcat-9.0.33.tar.gz /usr/local/ ADD jdk-8u221-linux-x64.rpm /usr/local/ RUN yum -y install vim ENV MYPATH /usr/local WORKDIR $MYPATH ENV JAVA_HOME /usr/local/jdk1.8.0_11 ENV CLASSPATH $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar ENV CATALINA_HOME /usr/local/apache-tomcat-9.0.33 ENV CATALINA_BASH /usr/local/apache-tomcat-9.0.33 # 配置环境变量 ENV PATH $PATH:$JAVA_HOME/bin:$CATALINA_HOME/lib:/CATALINA_HOME/bin EXPOSE 8080 CMD /usr/local/apache-tomcat-9.0.33/bin/startup.sh && tail -F /usr/local/apache-tomcat-9.0.33/bin/logs/catalina.out
构建镜像
1 # docker build -t diytomcat .
本地测试
curl localhost:9090
发布自己的镜像
DockerHub
地址hub.docker.com 注册自己的账号!
确定这个账号可以登录
在服务器上提交自己的镜像
1 2 3 4 5 6 7 8 9 10 11 [root@CZP ~]# docker login --help Usage: docker login [OPTIONS] [SERVER] Log in to a Docker registry. If no server is specified, the default is defined by the daemon. Options: -p, --password string Password --password-stdin Take the password from stdin -u, --username string Username
登录完毕就可以提交镜像了,就是一步 docker push
1 2 3 4 5 # push自己的镜像到服务器上一定要带上版本号 [root@CZP ~]# docker push czp/centos:1.0 docker tag [id] [tag] 为容器添加一个版本
提交到阿里云镜像仓库
登录阿里云
找到容器镜像服务
创建命名空间
创建容器镜像
浏览阿里云
小结
Docker网络 理解docker0
测试
三个网络
1 # 问题: docker 是如何处理容器网络访问的?
原理
我们每启动一个docker容器,docker就会给docker容器分配一个ip,我们只要安装了docker,就会有一个网卡docker0,桥接模式,使用的技术是evth-pair技术!
再次测试 ip addr
再启动一个容器
1 2 3 4 # 我们发现这个容器带来网卡, 都是一对对的 # evth-pair 就是一对虚拟机设备接口,他们都是成对出现的,一端连着协议,一端彼此相连 # 正因为有这个特性,veth-pair 充当桥梁,连接各种虚拟网络设备的 # openStac,Docker容器之间的连接,OVS的连接,都是使用 evth-pair 技术
我们来测试一下
结论: tomcat01和tomcat02是共用的一个路由器,docker0
所有的容器不指定网络的情况下,都是docker0路由的,docker会给我们的容器分配一个默认的可用IP
小结
Docker 使用的是Linux的桥接,宿主机中是一个Docker容器的网桥,docker0
Docker中所有的网络接口都是虚拟的,虚拟的转发效率高
只要容器删除,对应网桥的一对就没了
–link
思考一个场景,我们编写了一个微服务,database url=ip: 项目不重启,数据库IP换掉了,我们希望可以通过名字来访问服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@CZP ~]# docker exec -it tomcat02 ping tomcat01 ping: tomcat01: Name or service not known # 如何可以解决呢? # 通过 --link 就可以解决网络问题 [root@CZP ~]# docker exec -it tomcat03 ping tomcat02 PING tomcat02 (172.18.0.4) 56(84) bytes of data. 64 bytes from tomcat02 (172.18.0.4): icmp_seq=1 ttl=64 time=0.128 ms 64 bytes from tomcat02 (172.18.0.4): icmp_seq=2 ttl=64 time=0.097 ms 64 bytes from tomcat02 (172.18.0.4): icmp_seq=3 ttl=64 time=0.091 ms 64 bytes from tomcat02 (172.18.0.4): icmp_seq=4 ttl=64 time=0.109 ms 64 bytes from tomcat02 (172.18.0.4): icmp_seq=5 ttl=64 time=0.097 ms 64 bytes from tomcat02 (172.18.0.4): icmp_seq=6 ttl=64 time=0.096 ms 64 bytes from tomcat02 (172.18.0.4): icmp_seq=7 ttl=64 time=0.092 ms 64 bytes from tomcat02 (172.18.0.4): icmp_seq=8 ttl=64 time=0.094 ms 64 bytes from tomcat02 (172.18.0.4): icmp_seq=9 ttl=64 time=0.102 ms ^C --- tomcat02 ping statistics --- 9 packets transmitted, 9 received, 0% packet loss, time 1007ms rtt min/avg/max/mdev = 0.091/0.100/0.128/0.015 ms # 反向是否可以ping通吗 [root@CZP ~]# docker exec -it tomcat02 ping tomcat03
本地探究 – link 就是我们在host配置中增加了一个172.18.0.3 tomcat02 312857784cd4
我们现在玩Docker已经不建议使用–link了!
自定义网络,不使用docker0!
docker0问题: 它不支持容器名连接访问!
自定义网络
查看所有的docker网络
网络模式
bridge : 桥接 docker 大桥
none: 不配置网络
host: 和宿主机共享网络
container: 容器内网络联通!
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 # 直接启动的命令 --net brodge,默认docker0 docker run -d -P --name tomcat01 --net bridge tomcat # docker0的特点: 默认的,域名是不能访问的, --link可以打通连接 # 自定义 [root@CZP ~]# docker network create --help Usage: docker network create [OPTIONS] NETWORK Create a network Options: --attachable Enable manual container attachment --aux-address map Auxiliary IPv4 or IPv6 addresses used by Network driver (default map[]) --config-from string The network from which copying the configuration --config-only Create a configuration only network -d, --driver string Driver to manage the Network (default "bridge") --gateway strings IPv4 or IPv6 Gateway for the master subnet --ingress Create swarm routing-mesh network --internal Restrict external access to the network --ip-range strings Allocate container ip from a sub-range --ipam-driver string IP Address Management Driver (default "default") --ipam-opt map Set IPAM driver specific options (default map[]) --ipv6 Enable IPv6 networking --label list Set metadata on a network -o, --opt map Set driver specific options (default map[]) --scope string Control the network's scope --subnet strings Subnet in CIDR format that represents a network segment [root@CZP ~]# docker network create --driver bridge --subnet 192.168.0.0/16 --gateway 192.168.0.1 mynet 677fae13a48c634dc03c56641b9ba31354846d31a196fdcb92c9ef6ddff73150 [root@CZP ~]# docker network ls NETWORK ID NAME DRIVER SCOPE 228826a97a0b bridge bridge local c3b4884cd4db host host local 677fae13a48c mynet bridge local 35885200f93d none null local
我们自己的网络就创建好了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 [root@CZP ~]# docker run -d -P --name tomcat-net-01 --net mynet tomcat:9.0 336dd072ca17ac1adf514c44c8dcbd3358146d6d60667f3a0f99dbbb3e305f09 [root@CZP ~]# docker run -d -P --name tomcat-net-02 --net mynet tomcat:9.0 2cea3bb29350ae99ce26c1bf6f8d1f2dcfb25bf8042193263ce275308e9eb42d [root@CZP ~]# docker network inspect mynet [ { "Name": "mynet", "Id": "677fae13a48c634dc03c56641b9ba31354846d31a196fdcb92c9ef6ddff73150", "Created": "2020-06-14T16:49:14.554786193+08:00", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "192.168.0.0/16", "Gateway": "192.168.0.1" } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": { "2cea3bb29350ae99ce26c1bf6f8d1f2dcfb25bf8042193263ce275308e9eb42d": { "Name": "tomcat-net-02", "EndpointID": "ebff8e9ef22bd3d66d0de4229d1f3a3c610785b23005294f60f96f3089d52c3d", "MacAddress": "02:42:c0:a8:00:03", "IPv4Address": "192.168.0.3/16", "IPv6Address": "" }, "336dd072ca17ac1adf514c44c8dcbd3358146d6d60667f3a0f99dbbb3e305f09": { "Name": "tomcat-net-01", "EndpointID": "69451bb0c95ed27d207cd2bade9c57fd2625c245b8b8cb3e5d0dea530a368683", "MacAddress": "02:42:c0:a8:00:02", "IPv4Address": "192.168.0.2/16", "IPv6Address": "" } }, "Options": {}, "Labels": {} } ]
现在不使用–link也可以ping名字了,推荐使用这种网络
1 2 3 4 5 6 7 [root@CZP ~]# docker exec tomcat-net-01 ping tomcat-net-02 PING tomcat-net-02 (192.168.0.3) 56(84) bytes of data. 64 bytes from tomcat-net-02.mynet (192.168.0.3): icmp_seq=1 ttl=64 time=0.080 ms 64 bytes from tomcat-net-02.mynet (192.168.0.3): icmp_seq=2 ttl=64 time=0.096 ms 64 bytes from tomcat-net-02.mynet (192.168.0.3): icmp_seq=3 ttl=64 time=0.086 ms ^C [root@CZP ~]#
好处:
不同的集群使用不同的集群,保证集群之间是安全和健康的
网络联通
1 2 3 # 测试打通 tomcat01到tomcat-net-01 # 连通之后就是将 tomcat01 放到了mynet网络下 # 一个容器两个ip 阿里云: 公网ip 私网ip
这样容器之间就可以ping通了
实战 redis集群部署
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 # 创建网卡 docker network create --subnet 172.38.0.0/16 redis # 通过脚本创建六个redis配置 for port in $(seq 1 6);\ do \ mkdir -p /mydata/redis/node-${port}/conf touch /mydata/redis/node-${port}/conf/redis.conf cat << EOF >> /mydata/redis/node-${port}/conf/redis.conf port 6379 bind 0.0.0.0 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 cluster-announce-ip 172.38.0.1${port} cluster-announce-port 6379 cluster-announce-bus-port 16379 appendonly yes EOF done # 通过脚本运行六个redis for port in $(seq 1 6);\ do \ docker run -p 637${port}:6379 -p 1637${port}:16379 --name redis-${port} \ -v /mydata/redis/node-${port}/data:/data \ -v /mydata/redis/node-${port}/conf/redis.conf:/etc/redis/redis.conf \ -d --net redis --ip 172.38.0.1${port} redis:5.0.9-alpine3.11 redis-server /etc/redis/redis.conf done # 停止redis并删除容器 for port in $(seq 1 6);\ do \ docker stop redis-${port}; \ docker rm redis-${port}; done docker exec -it redis-1 /bin/sh #redis默认没有bash redis-cli --cluster create 172.38.0.11:6379 172.38.0.12:6379 172.38.0.13:6379 172.38.0.14:6379 172.38.0.15:6379 172.38.0.16:6379 --cluster-replicas 1
集群搭建成功
SpringBoot微服务打包Docker镜像
构建springBoot项目 打包应用 编写dockerfile 构建镜像 发布运行