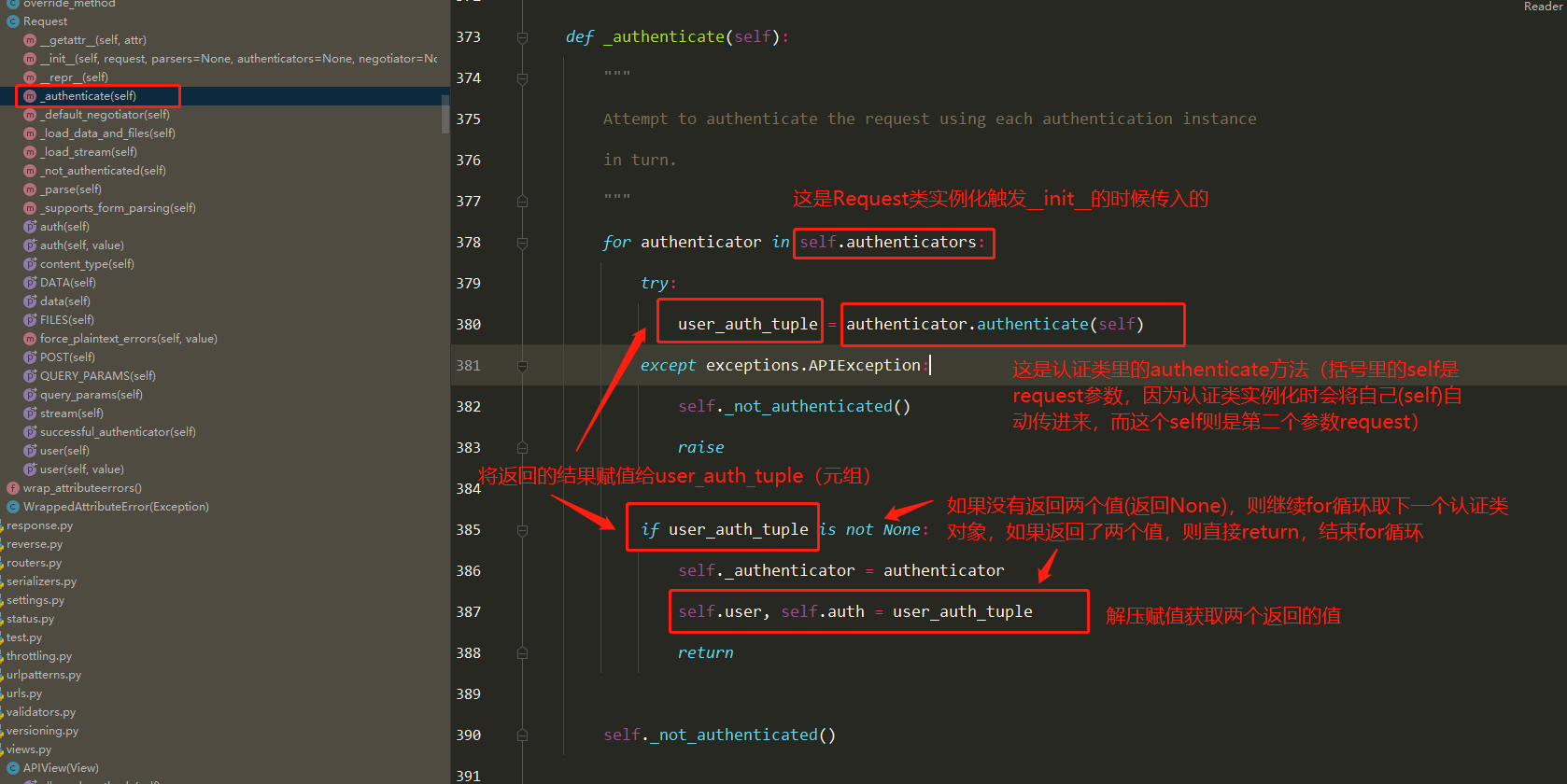
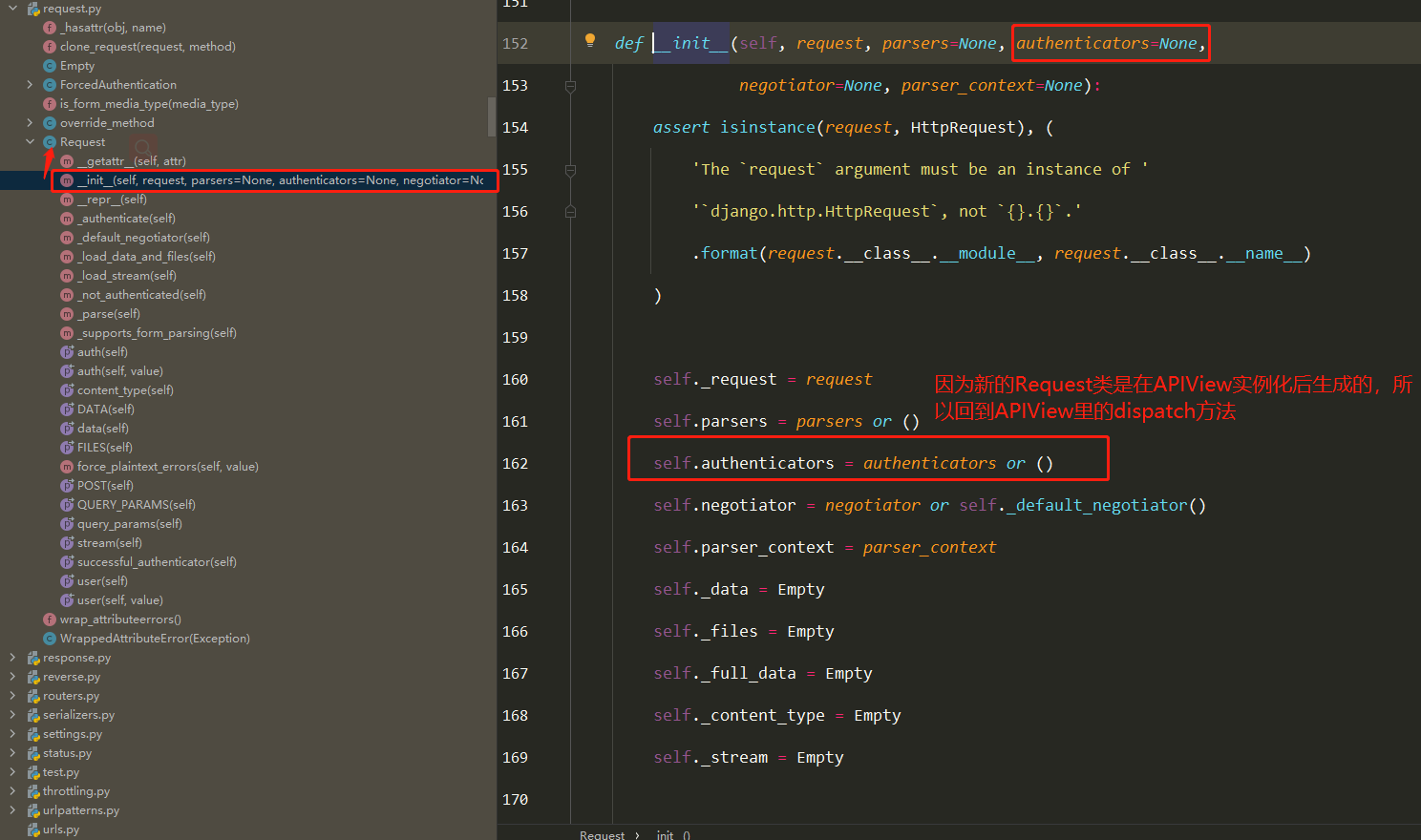
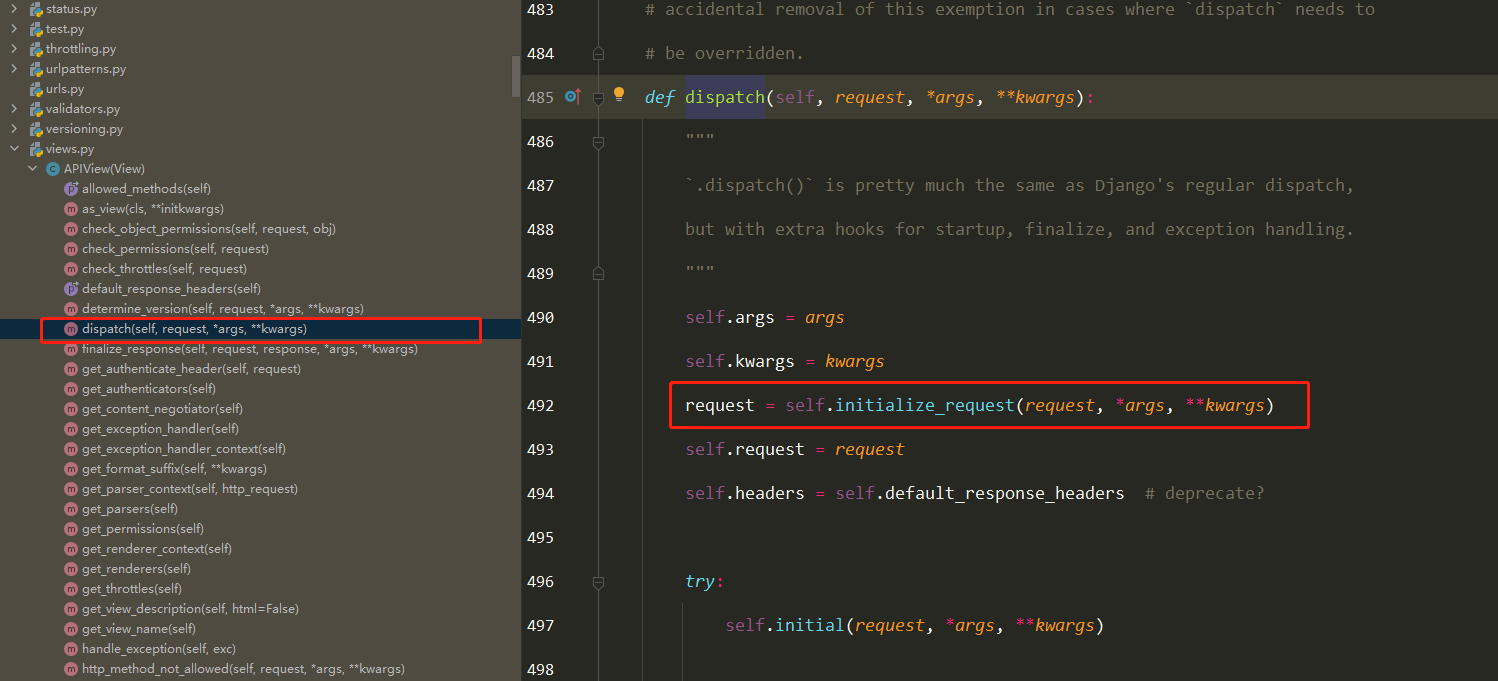
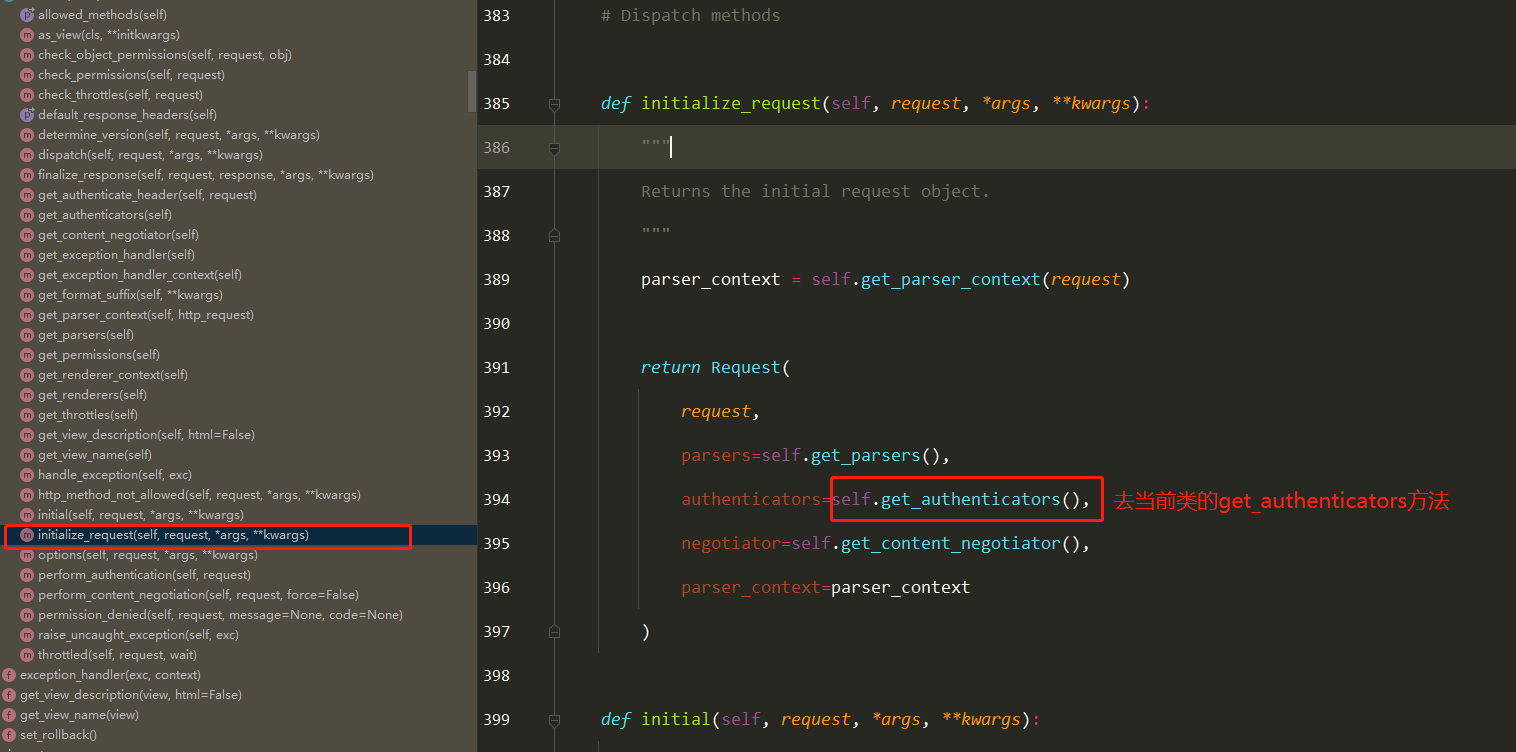
DRF APIView请求生命周期流程图
drf入门规范 Web应用模式 前后端不分离
前后端分离(主流)
API接口 通过网络,规定了前后台信息交互规则的url链接,也就是前后台信息交互的媒介
四大特点
==url==
==请求方式==
get、post、put、patch、delete
==请求参数==
json或xml(老项目)格式的key-value类型数据
==相应结果==
接口测试工具:Postman 官网下载 :https://www.getpostman.com/downloads/
RESTful API规范(3星) 写接口的规范,大部分接口都会按照这个规范去写(Web API接口的设计风格)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 https://api.baidu.com https://www.baidu.com/api https://api.baidu.com/v1 https://api.baidu.com/v2 https://api.baidu.com/users https://api.baidu.com/books https://api.baidu.com/book '查询操作' : get '新增操作' : post '修改操作' : put '删除操作' : delete https://api.baidu.com/books - get请求:获取所有书 https://api.baidu.com/books/1 - get请求:获取主键为1 的书 https://api.baidu.com/books - post请求:新增一本书书 https://api.baidu.com/books/1 - put请求:整体修改主键为1 的书 https://api.baidu.com/books/1 - patch请求:局部修改主键为1 的书 https://api.baidu.com/books/1 - delete请求:删除主键为1 的书 https://api.example.com/v1/zoos?limit=10 :指定返回记录的数量 https://api.example.com/v1/zoos?offset=10 :指定返回记录的开始位置、 https://api.example.com/v1/zoos?animal_type_id=1 :指定筛选条件 { status:200 } { status:200 msg: "无权限操作" } GET /collection:返回资源对象的列表(数组) GET /collection/resource:返回单个资源对象 POST /collection:返回新生成的资源对象 PUT /collection/resource:返回完整的资源对象 PATCH /collection/resource:返回完整的资源对象 DELETE /collection/resource:返回一个空文档 { "status" : 0 , "msg" : "ok" , "results" :[ { "name" :"肯德基(罗餐厅)" , "img" : "https://image.baidu.com/kfc/001.png" } ] }
drf介绍与安装 1 2 3 4 5 6 7 8 9 Python(3.5 、3.6 、3.7 、3.8 、3.9 ) Django(2.2 、3.0 、3.1 ) 2. x用的多,1. x(老项目)
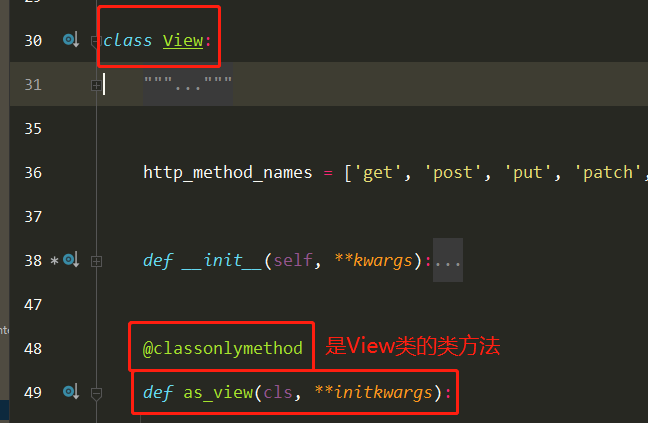
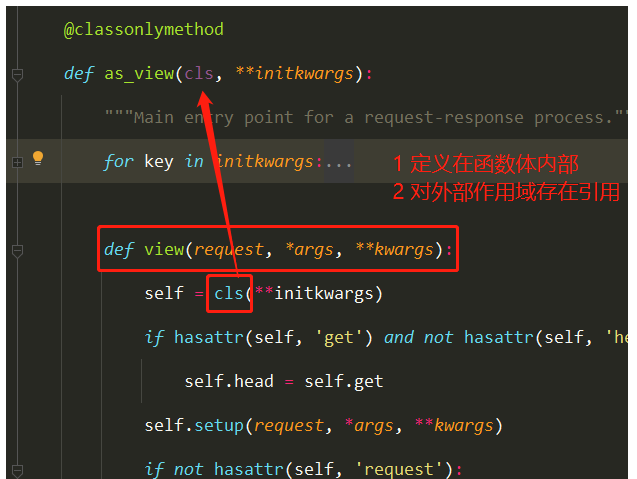
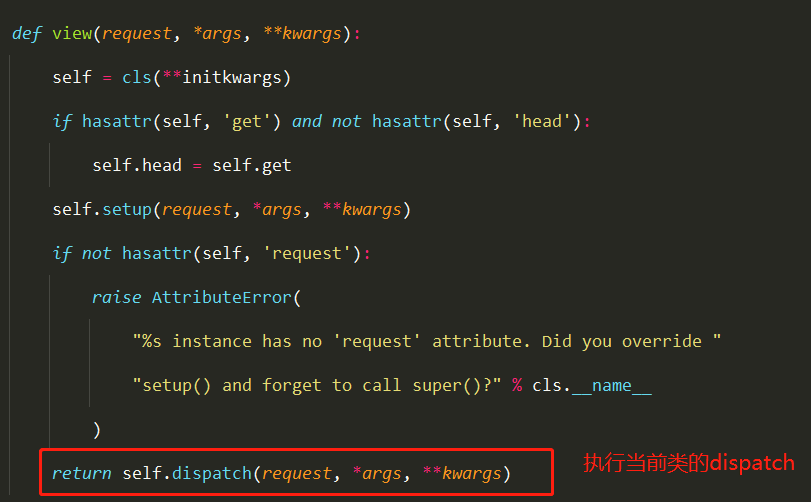
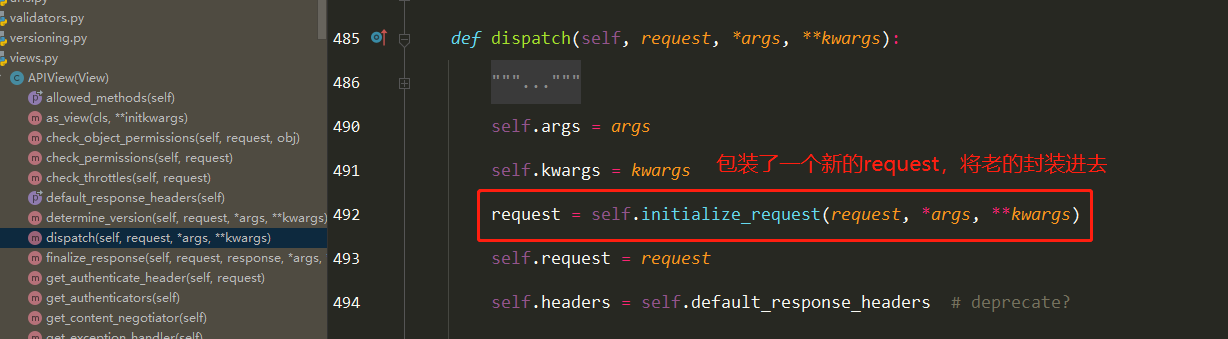
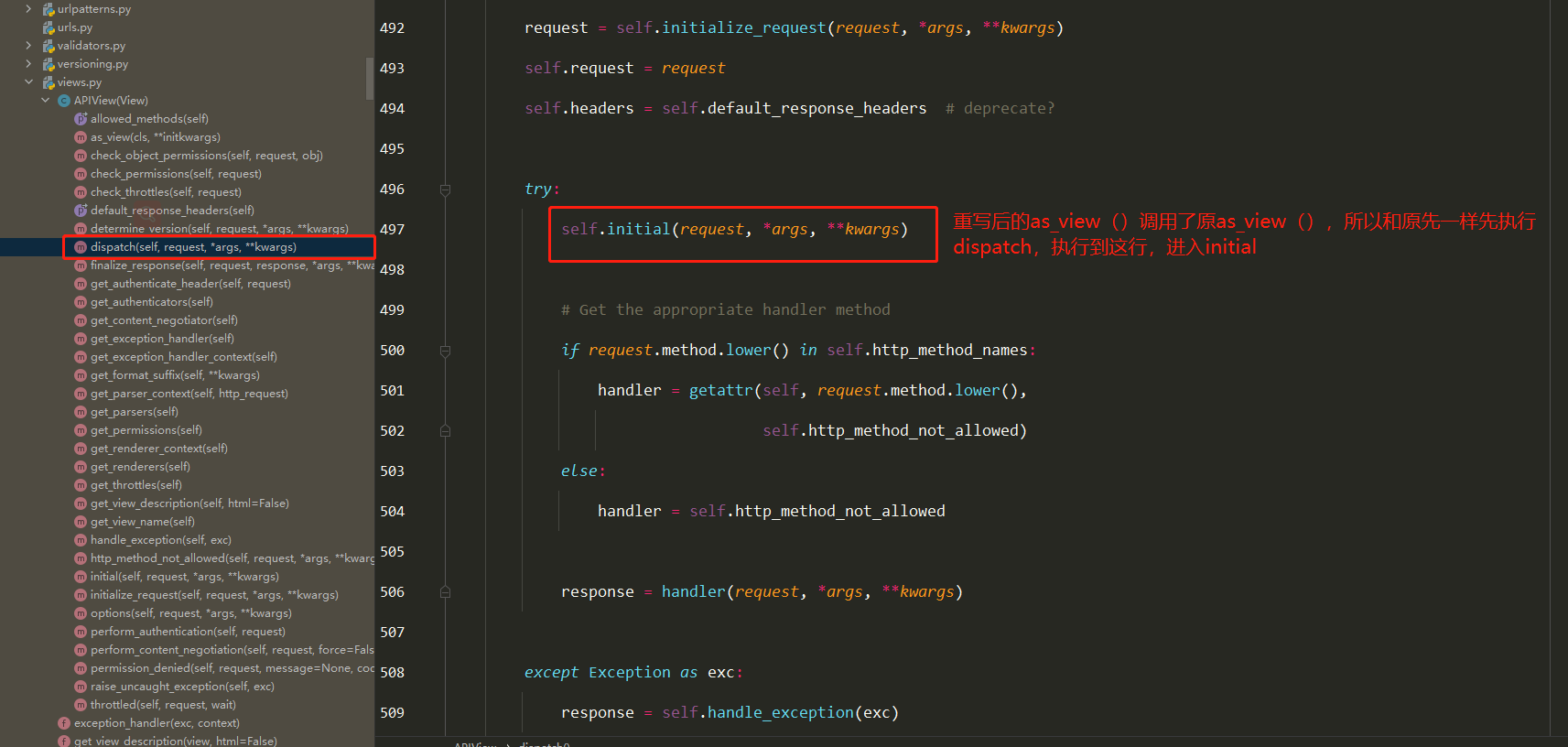
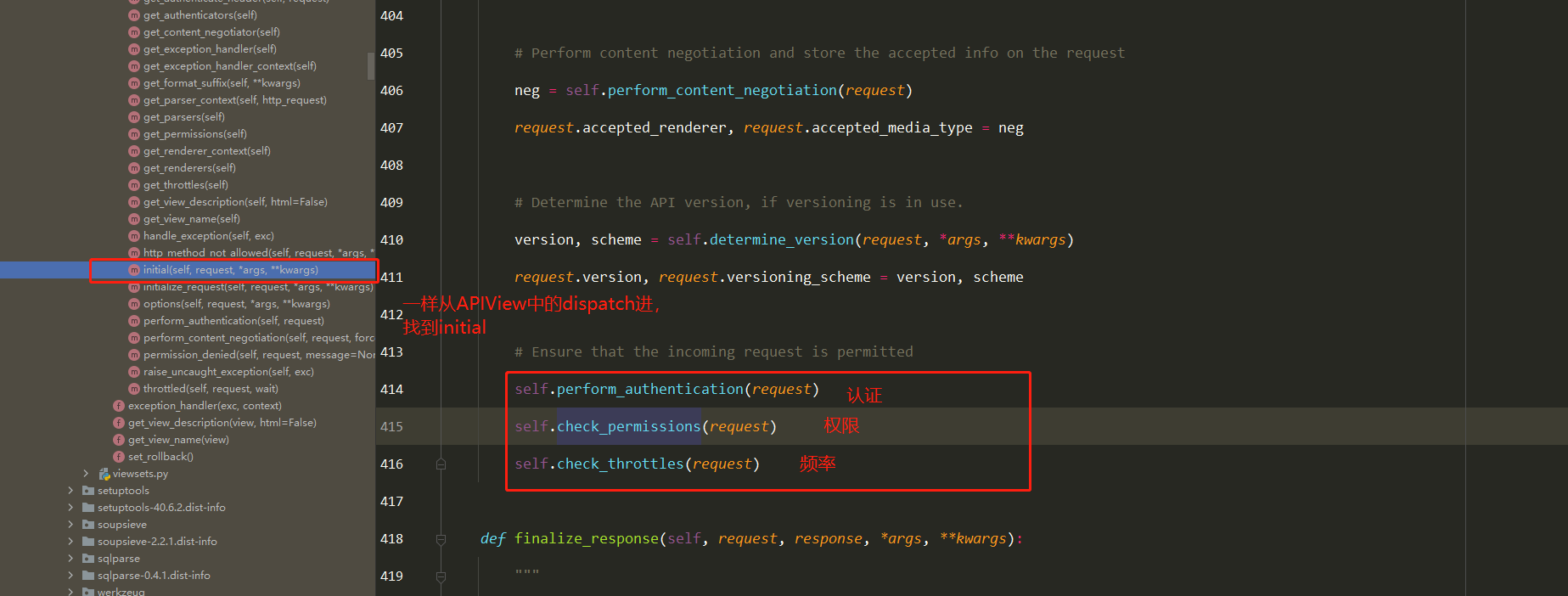
CBV源码分析(2星) 1 views.Book.as_view()执行完,一定是一个函数的内存地址
2 as_view是View类的类方法,类来调用
3 as_view中的view是一个闭包函数
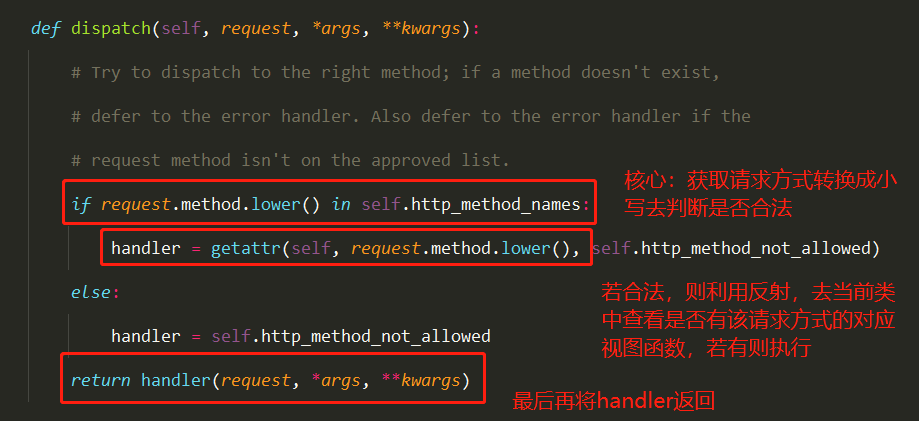
4 执行了View类的dispatch
拓展
1 2 3 4 5 6 7 8 例如 def dispatch (self, request, *args, **kwargs ): response = super ().dispatch(request, *args, **kwargs) return response
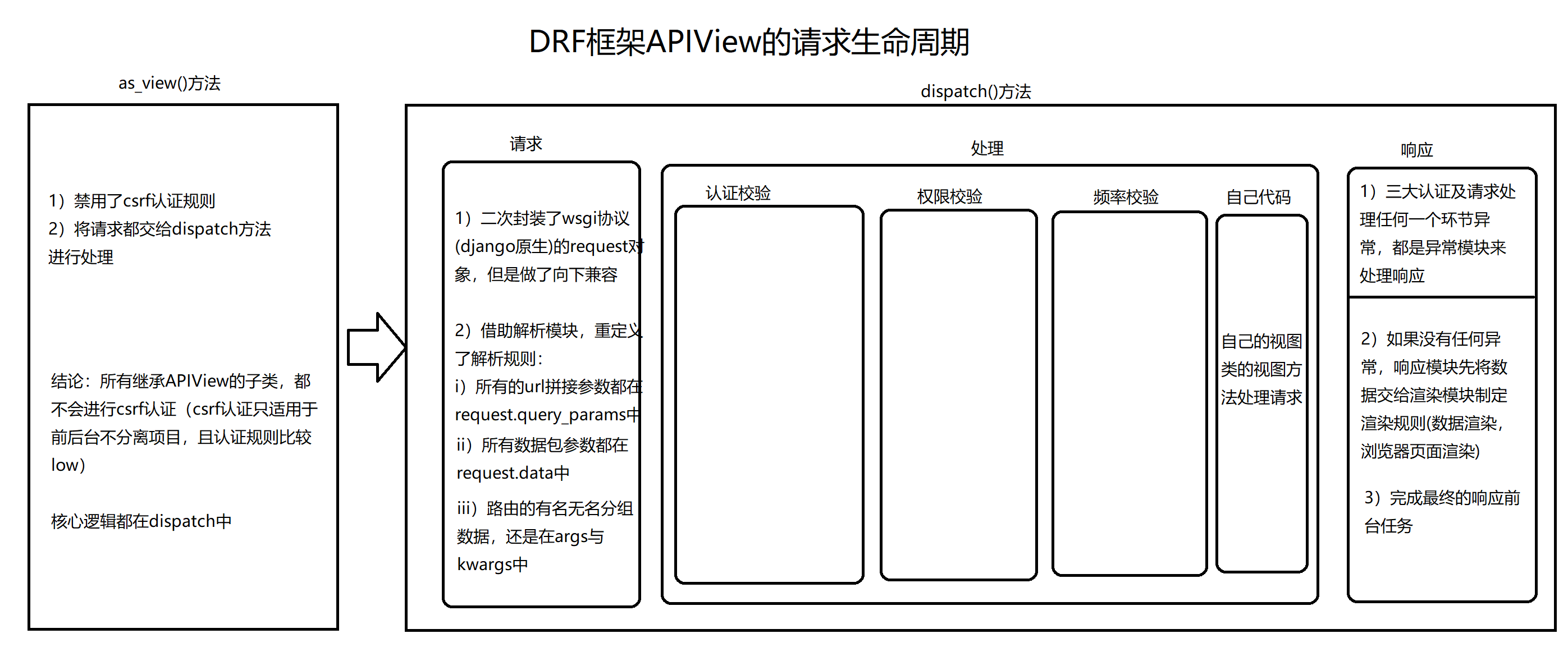
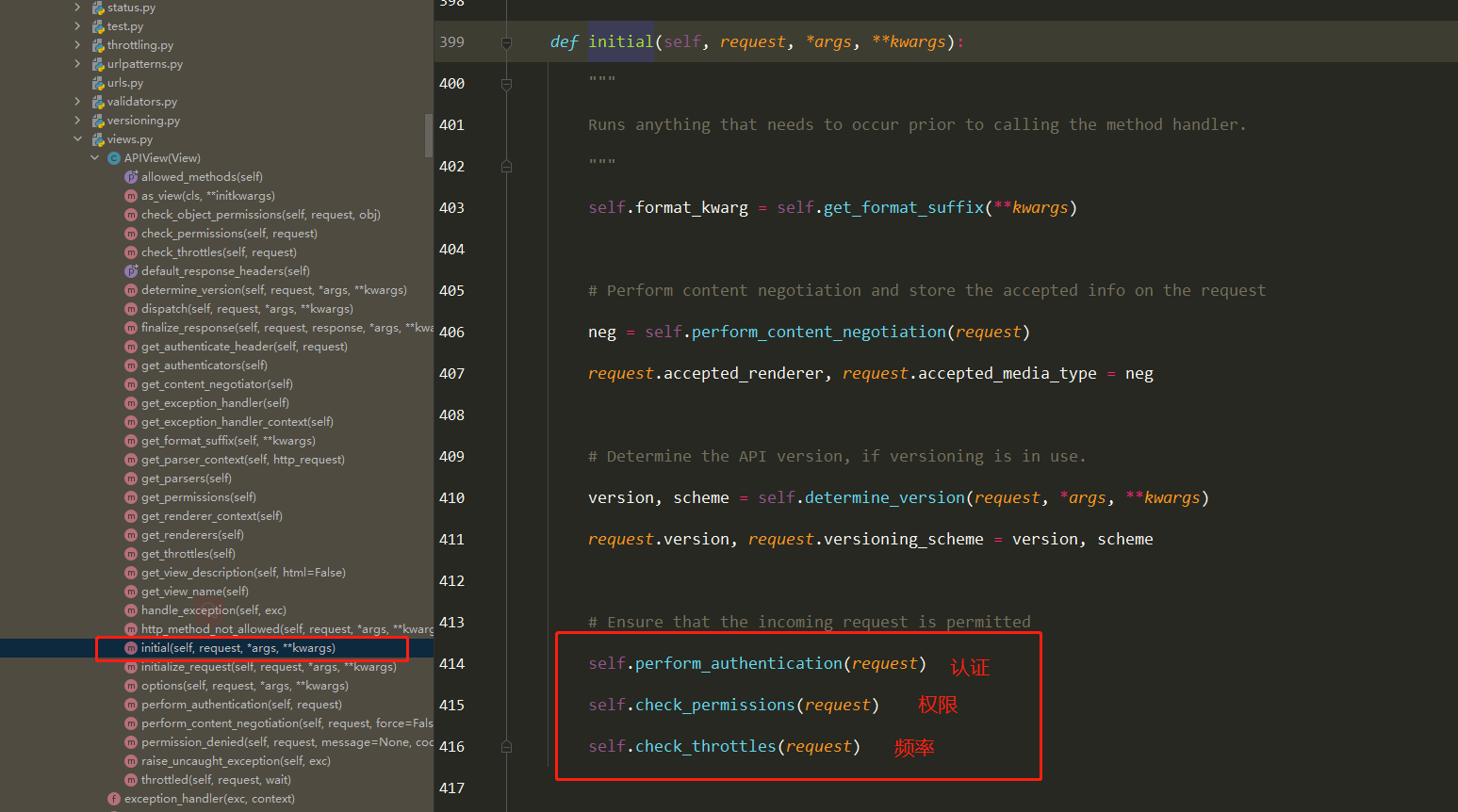
drf基本使用及流程分析(3星) 继承APIView使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from rest_framework.views import APIViewfrom .models import Studentfrom .serializers import Student_serializersfrom rest_framework.response import Responseclass Student_serializers_APIView (APIView ): def get (self, request, *args, **kwargs ): student_list = Student.objects.all () ser = Student_serializers(instance=student_list, many=True ) return Response(ser.data) def post (self, request, *args, **kwargs ): ser = Student_serializers(data=request.data) if ser.is_valid(): ser.save() return Response(ser.data)
APIView的执行流程
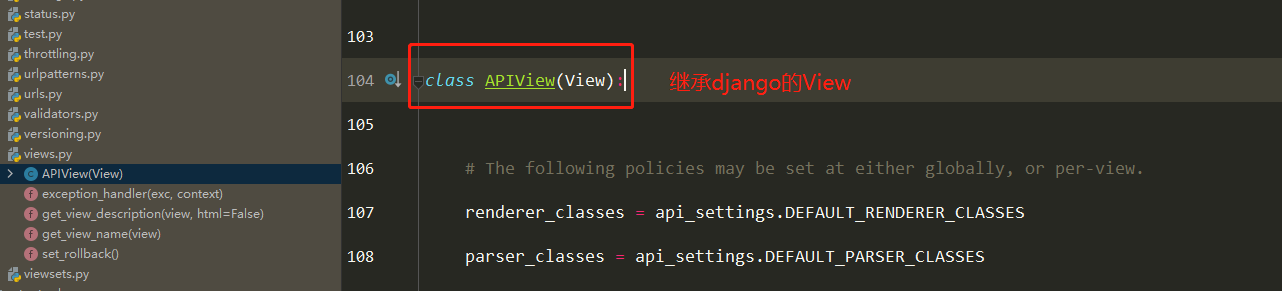
==1 APIView继承了django的View==
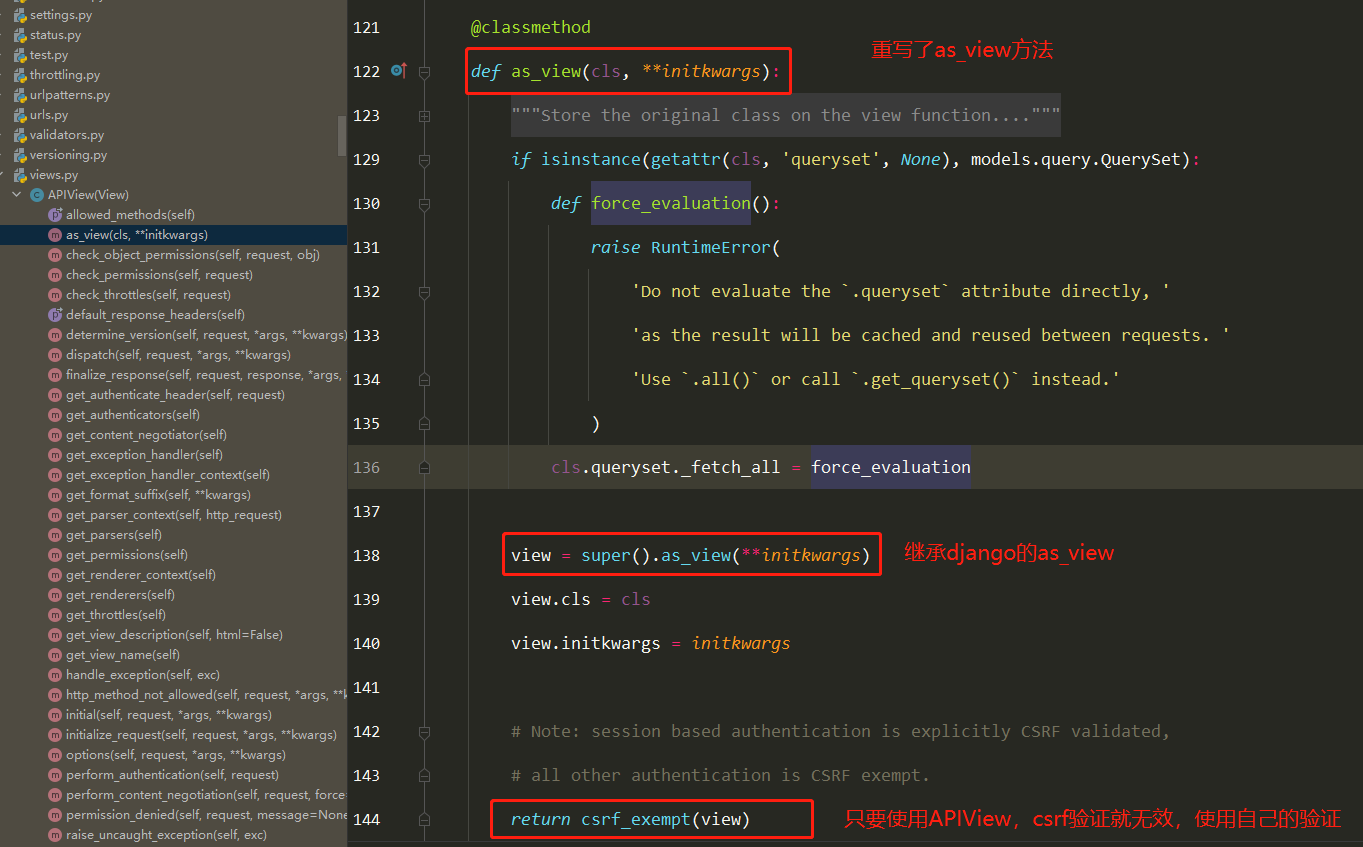
==2 APIView中重写了as_view==
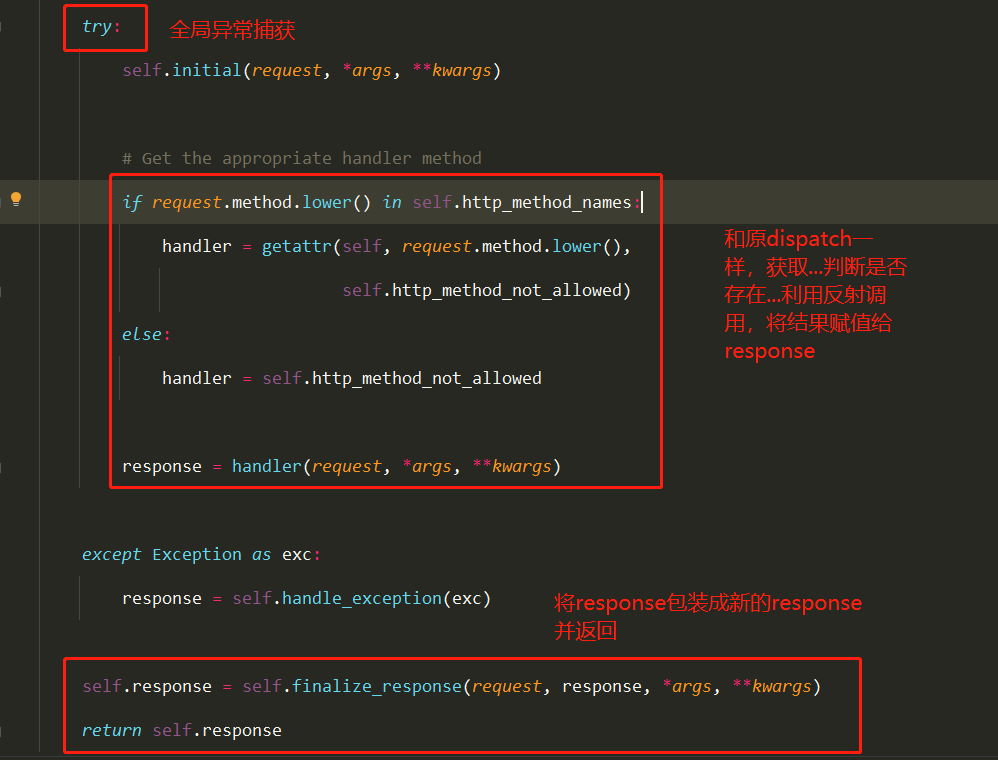
==3 执行self.dispatch() —> APIView的dispatch==
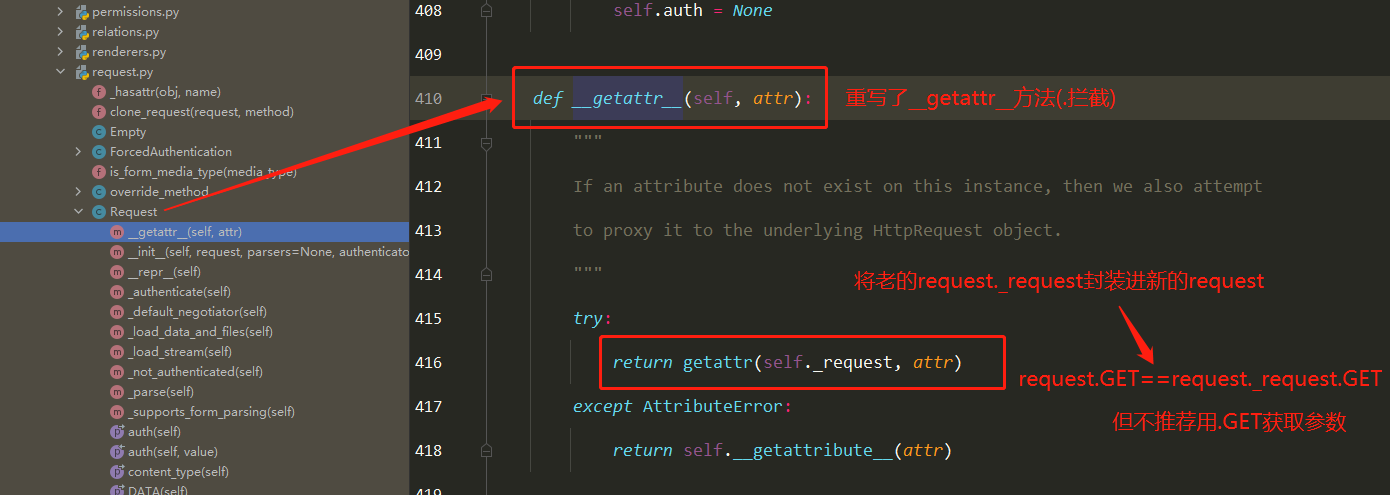
==4 在视图类中使用的request对象是新的request对象,而老的则是request._request==
==5 新的request对象中有一个属性:data==
1 2 3 4 5 6 ''' 1 data是post请求携带的数据 ---> 字典 2 无论是什么编码格式,只要是post提交的数据,都在request.data中 3 以后再取值,都从request.data中取 '''
==6 结论:继承了APIView后,request对象变成新的request,其他大部分和原来一样使用==
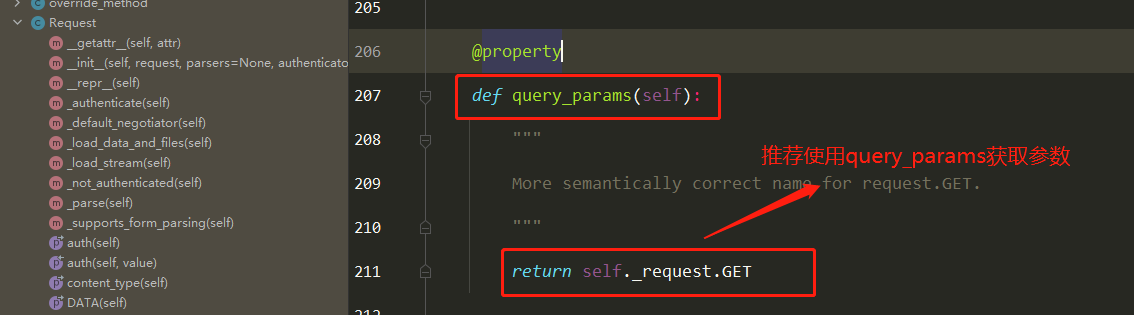
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 1 以后如果使用了drf,继承APIView(drf提供了很多view,他们都是继承自APIView) 注意: ''' 包装出了一个新的request,在视图函数中使用时,跟原先没有区别 取post提交的数据,不要再从request.POST中取了,要从request.data中取 取get提交的参数,尽量不从request。GET中取了,要从request.query_params中取 ''' 2 Request类(drf的)需要掌握 2.1 request.data 2.2 request.query_params 2.3 request.FILES 3 APIView类 ''' 包装了新的request 执行了认证、权限、频率... 处理了全局异常 包装了response对象 '''
drf配置 1 2 3 4 5 6 7 REST_FRAMEWORK={ ... }
序列化组件 介绍 作用
1 2 3 4 5 1 序列化,序列化器(类)会把模型对象(Book对象,Queryset对象)转换成字典,经过response以后变成json字符串2 反序列化,把客户端发送过来的数据,经过request以后变成字典(request.data),序列化器(类)可以把字典转成模型3 反序列化,完成数据校验功能
本质
序列化器之Serializer类的使用(跟表模型没有必然联系)(5星) 视图类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from django.shortcuts import renderfrom rest_framework.views import APIViewfrom .models import Studentfrom .serializers import Student_serializersfrom rest_framework.response import Responseclass Student_serializers_APIView (APIView ): def get (self, request, *args, **kwargs ): student_list = Student.objects.all () ser = Student_serializers(instance=student_list, many=True ) return Response(ser.data) def post (self, request, *args, **kwargs ): ser = Student_serializers(data=request.data) if ser.is_valid(): ser.save() return Response(ser.data) class Student_Detial_serializers_APIView (APIView ): def get (self, request, pk ): student = Student.objects.filter (pk=pk).first() ser = Student_serializers(instance=student) return Response(ser.data) def put (self, request, pk ): student = Student.objects.filter (pk=pk).first() ser = Student_serializers(instance=student, data=request.data) if ser.is_valid(): ser.save() return Response(ser.data) def delete (self, request, pk ): Student.objects.filter (pk=pk).delete() return Response()
序列化类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from rest_framework import serializersfrom .models import Studentclass Student_serializers (serializers.Serializer ): name = serializers.CharField(max_length=32 ) age = serializers.IntegerField() def create (self, validated_data ): student = Student.objects.create(**validated_data) return student def update (self, instance, validated_data ): instance.name = validated_data.get('name' ) instance.age = validated_data.get('age' ) instance.save() return instance
路由
1 2 3 4 5 6 7 8 9 10 11 from django.contrib import adminfrom django.urls import pathfrom app01 import viewsfrom django.views import Viewurlpatterns = [ path('admin/' , admin.site.urls), path('student/' , views.Student_serializers_APIView.as_view()), path('student/<int:pk>' , views.Student_Detial_serializers_APIView.as_view()) ]
模型
1 2 3 4 5 6 7 8 from django.db import modelsclass Student (models.Model ): name = models.CharField('姓名' , max_length=32 ) age = models.IntegerField('年龄' )
Serializers高级使用(5星) 1 source字段的作用
1 2 3 4 5 6 ''' 注: source如果是字段,会显示字段,如果是方法,会执行方法,不用加括号 '''
2 SerializerMethodFidld使用方法
1 2 3 4 5 course_detail = serializers.SerializerMethodField() def get_course_detail (self, obj ): return {'name' :obj.course.name,'teacher' :obj.course.course_teacher}
3 数据校验
==反序列化时需要进行数据校验==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 '使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或者保存成模型类对象' class BookInfoSerializer (serializers.Serializer ): """图书数据序列化器""" id = serializers.IntegerField(label='ID' , read_only=True ) btitle = serializers.CharField(label='名称' , max_length=20 ) bpub_date = serializers.DateField(label='发布日期' , required=False ) bread = serializers.IntegerField(label='阅读量' , required=False ) bcomment = serializers.IntegerField(label='评论量' , required=False ) image = serializers.ImageField(label='图片' , required=False ) def post (self, request, *args, **kwargs ): ser = Publish_modelserializers(request.data) if ser.is_valid(): ser.save() return Response(ser.data) else : return Response({msg:ser.errors.get('name' )}) ps: is_valid()方法还会在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True 参数开启,REST-framework接收到此异常,会向前端返回HTTP 400 Bad Request '注意' 验证顺序是:字段自己的限制 ---> 自己的局部钩子 --->(全部字段以及局部验证完毕以后再验证全局钩子) 3.2 .1 validate_字段名(局部钩子) def validate_name (self,name ): if name.startswith('sb' ): raise ValidationError('不能以sb开头' ) else : return name 3.2 .2 validate(全局钩子) def validate (self, attrs ): bread = attrs['bread' ] bcomment = attrs['bcomment' ] if bread < bcomment: raise serializers.ValidationError('阅读量小于评论量' ) return attrs 3.2 .3 validators(在字段中添加validators参数,补充验证行为) def about_django (value ): if 'django' not in value.lower(): raise serializers.ValidationError("图书不是关于Django的" ) class BookInfoSerializer (serializers.Serializer ): """图书数据序列化器""" id = serializers.IntegerField(label='ID' , read_only=True ) btitle = serializers.CharField(label='名称' , max_length=20 , validators=[about_django]) bpub_date = serializers.DateField(label='发布日期' , required=False ) bread = serializers.IntegerField(label='阅读量' , required=False ) bcomment = serializers.IntegerField(label='评论量' , required=False ) image = serializers.ImageField(label='图片' , required=False )
模型类序列化器ModelSerializer(跟表模型有关联)(5星) 1 介绍
1 drf为我们提供了一个ModelSerializer模型序列化器来帮助我们快速创建一个Serializer类
2 ModelSerializer与Serializer的区别
基于模型类自动生成一系列字段
基于模型类自动为Serializer生成validators,比如unique_together
包含默认的create()和update()的实现
3 使用
1 2 3 4 5 6 7 class Publish_modelserializers (serializers.ModelSerializer ): class Meta : model = Publish fields = '__all__' fields = ['id' ,'name' ] exclude = ['id' ] depth
4 重写字段
1 2 3 name = serializers.SerializerMethodField() def get_name (self, obj ): return "出版社 : " + obj.name
5 扩写字段(表模型中没有的字段)
1 2 3 4 5 6 7 8 9 ''' 注意: 嵌套反序列化时正常只能传pk值,需要两个字段(一个展示(read_only),一个添加数据(write_only)) 否则反序列化嵌套数据时报错 ''' name2 = serializers.SerializerMethodField() def get_name2 (self, obj ): return " 出版社2:东京出版社"
6 反序列化时,字段自己的校验规则,是映射表模型的
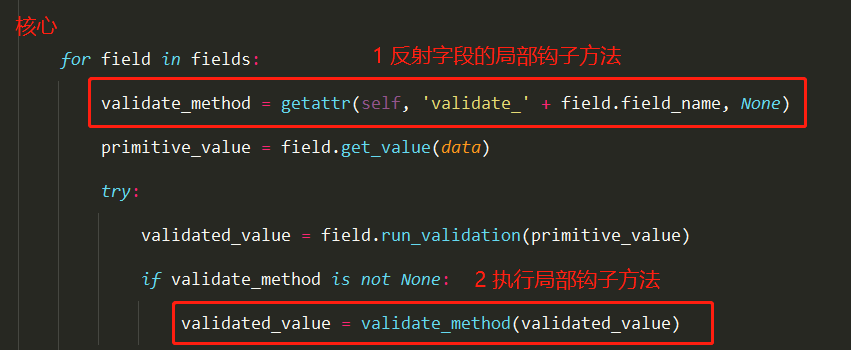
7 局部钩子与全局钩子(与Serializer一样)
8 write_only与read_only
1 2 3 name=serializers.CharField(write_only=True ) name=serializers.CharField(read_only=True )
9 extra_kwargs(添加额外参数选项)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Meta : model = Publish fields = '__all__' extra_kwargs = { 'name' :{ 'required' :True , 'min_length' :3 , 'write_only' :True 'error_messages' :{ 'required' :'必须填' , 'min_length' :'最少三位' }, 'addr' :{ 'read_only' :True 'required' :True } } }
序列化器字段和字段参数(2星) 常用字段类型:
字段
字段构造方式
BooleanField BooleanField()
NullBooleanField NullBooleanField()
CharField CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True)
EmailField EmailField(max_length=None, min_length=None, allow_blank=False)
RegexField RegexField(regex, max_length=None, min_length=None, allow_blank=False)
SlugField SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9 -]+
URLField URLField(max_length=200, min_length=None, allow_blank=False)
UUIDField UUIDField(format=’hex_verbose’) format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a"
IPAddressField IPAddressField(protocol=’both’, unpack_ipv4=False, **options)
IntegerField IntegerField(max_value=None, min_value=None)
FloatField FloatField(max_value=None, min_value=None)
DecimalField DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置
DateTimeField DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None)
DateField DateField(format=api_settings.DATE_FORMAT, input_formats=None)
TimeField TimeField(format=api_settings.TIME_FORMAT, input_formats=None)
DurationField DurationField()
ChoiceField ChoiceField(choices) choices与Django的用法相同
MultipleChoiceField MultipleChoiceField(choices)
FileField FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
ImageField ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
ListField ListField(child=, min_length=None, max_length=None)
DictField DictField(child=)
选项参数:
参数名称
作用
max_length 最大长度
min_lenght 最小长度
allow_blank 是否允许为空
trim_whitespace 是否截断空白字符
max_value 最小值
min_value 最大值
通用参数:
参数名称
说明
read_only 表明该字段仅用于序列化输出,默认False
write_only 表明该字段仅用于反序列化输入,默认False
required 表明该字段在反序列化时必须输入,默认True
default 反序列化时使用的默认值
allow_null 表明该字段是否允许传入None,默认False
validators 该字段使用的验证器
error_messages 包含错误编号与错误信息的字典
label 用于HTML展示API页面时,显示的字段名称
help_text 用于HTML展示API页面时,显示的字段帮助提示信息
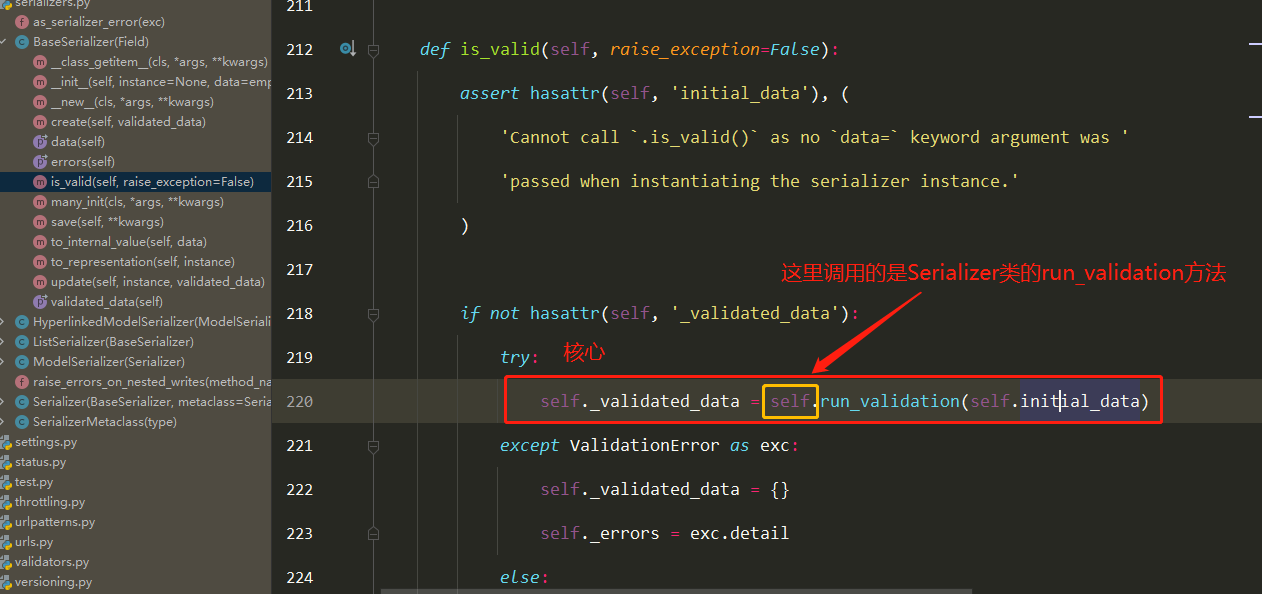
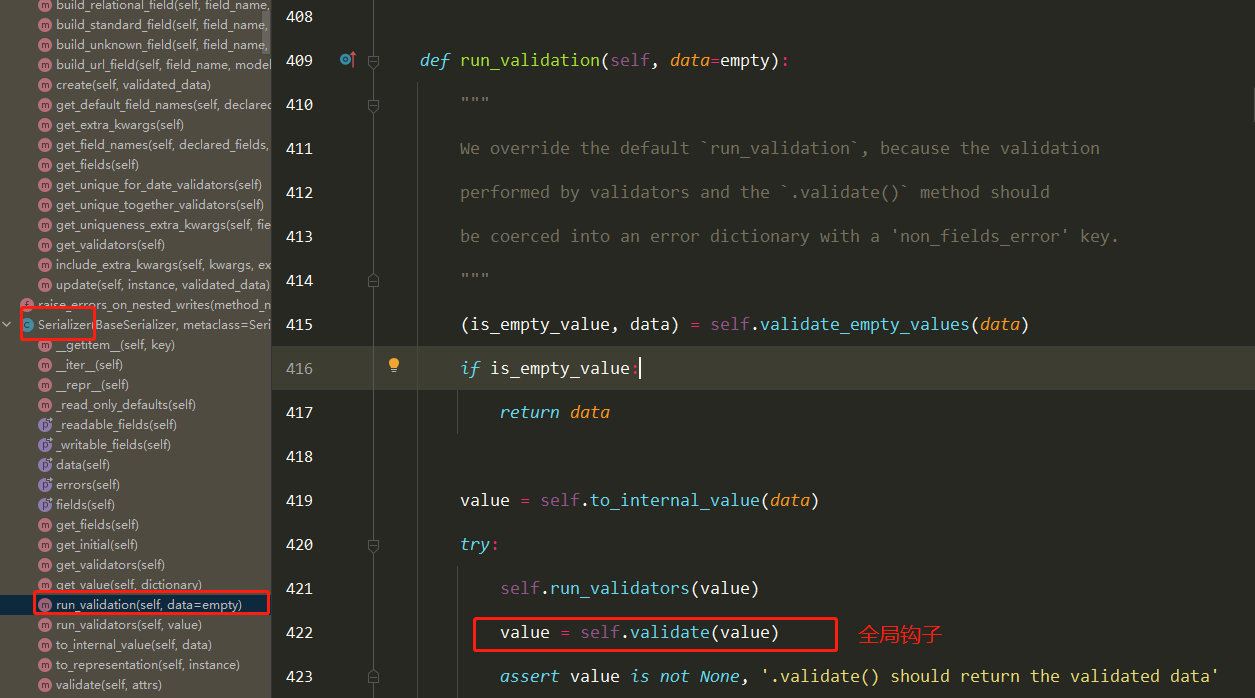
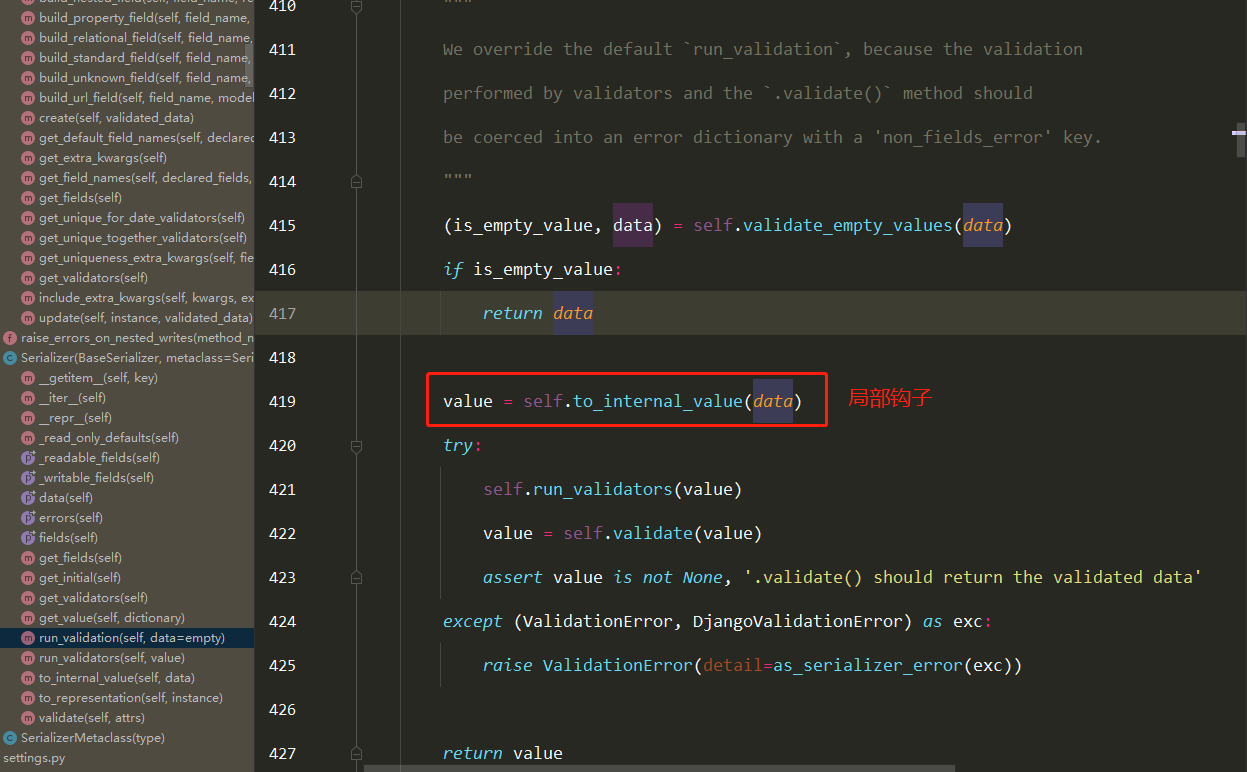
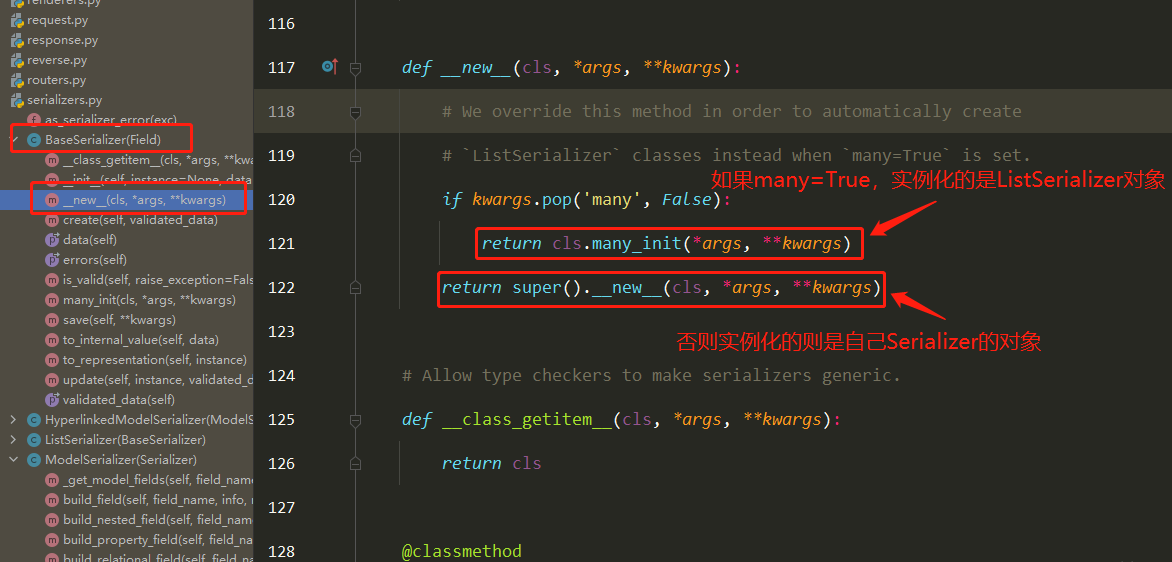
局部钩子和全局钩子源码分析(2星) 1 入口是ser.is_valid(),是BaseSerializer的方法
2 找到全局钩子
3 找到局部钩子
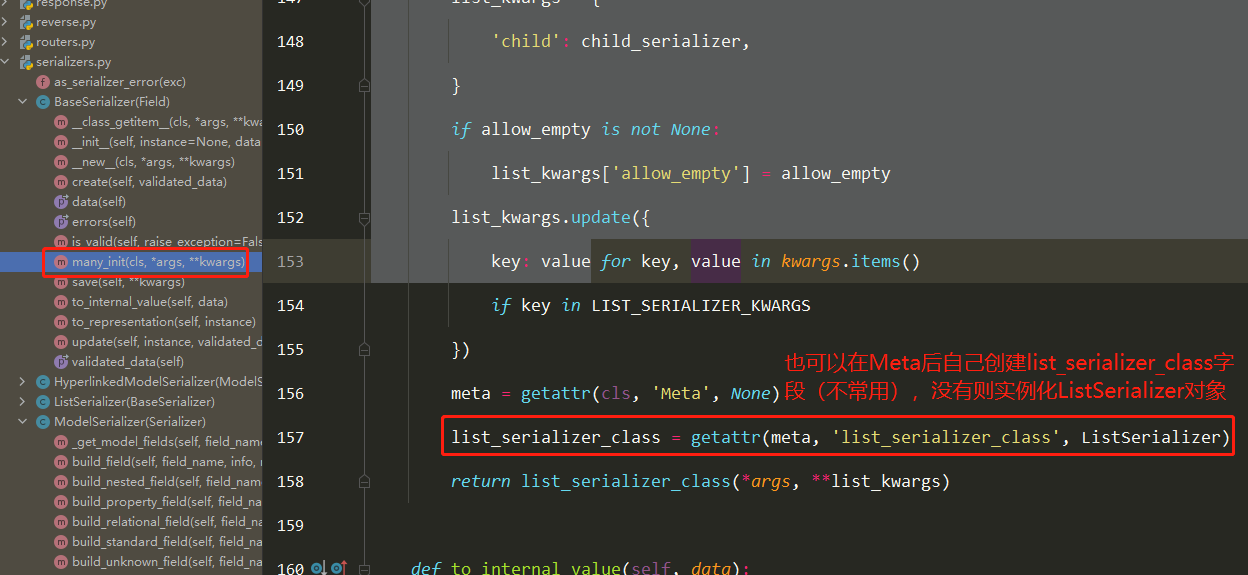
序列化组件部分源码分析(2星) 1 2 3 4 5 6 [ser1,ser2,ser3] ser
请求与响应(3星) drf请求全局和局部配置 请求默认支持三种编码格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 'DEFAULT_PARSER_CLASSES' : [ 'rest_framework.parsers.JSONParser' , 'rest_framework.parsers.FormParser' , 'rest_framework.parsers.MultiPartParser' ] from rest_framework.parsers import JSONParserclass BookView (ViewSetMixin,ListAPIView,CreateAPIView ): parser_classes = [JSONParser,]
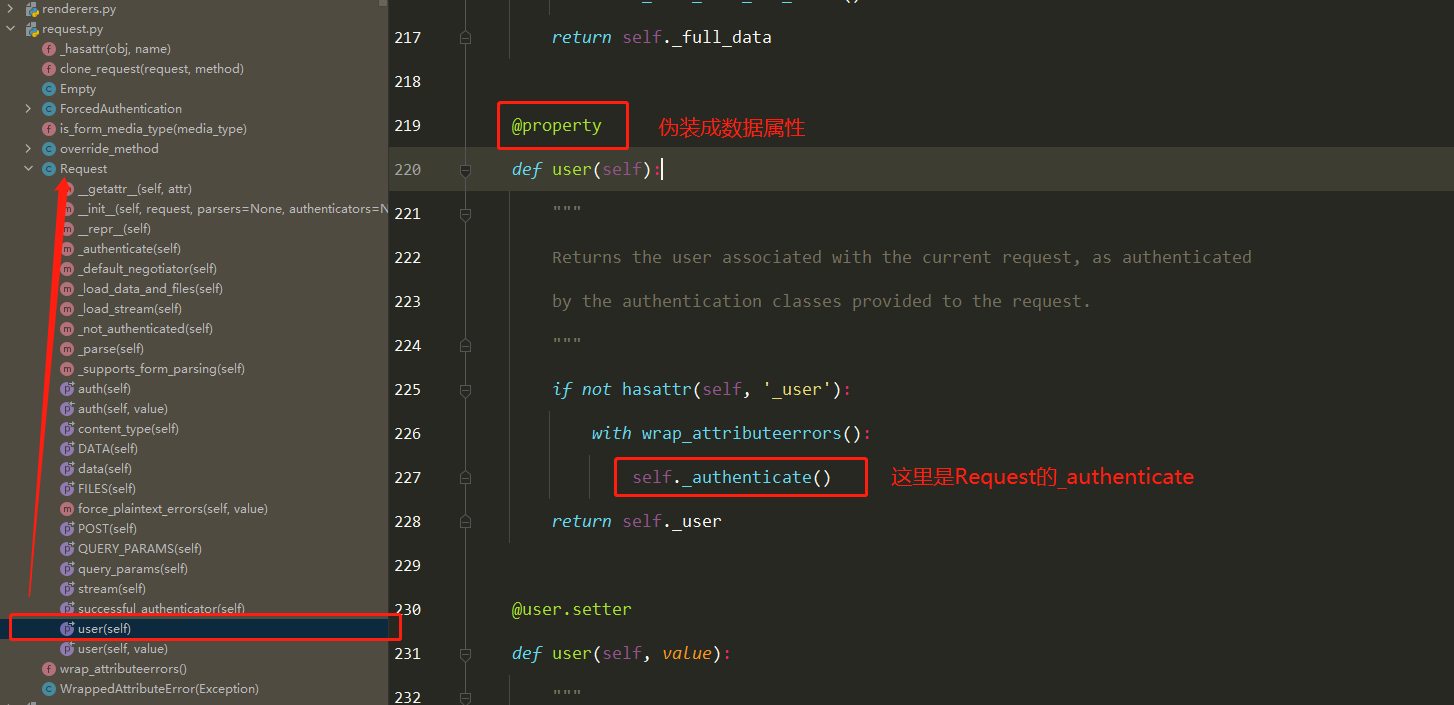
Request 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 rest-framework传入视图的request对象不再是Django默认的HttpRequest对象,而是rest-framework提供的扩展的HttpRequest类的Request类的对象 rest-framework提供了Parser解析器,在接收到请求后会自动根据Content-Type 指明的请求数据类型(如JSON、表单类型数据等)将请求数据进行parse解析,解析为类字典(QueryDict)对象保存在Request对象中 1 request.data: 包含了对POST、PUT、PATCH请求方式解析后的数据 利用了rest-framework的parsers解析器,不仅支持表单类型数据,也支持JSON类型数据 2 request.query_params request.query_params与Django的request.GET相同,只是更换了更正确的名字 ''' 重点: 1 继承APIView后,视图类中的request对象是新的request对象 2 request.data、request.query_params的使用 '''
Response 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 data=None status=None template_name=None headers=None exception=False content_type=None ''' 重点: data status headers ''' response={'code' :100 , 'msg' :'查询成功' , 'request' :ser.data} return Response(response,status=status.HTTP_201_CREATED,headers={'xxx' :"xxx" }) 1 通过配置,设置响应格式(浏览器模板样子、纯json) REST_FRAMEWORK={ 'DEFAULT_RENDERER_CLASSES' : [ 'rest_framework.renderers.JSONRenderer' , 'rest_framework.renderers.BrowsableAPIRenderer' , ] } 2 局部配置(只针对某一个视图函数) 在视图类上写 renderer_classes = [JSONRenderer] 3 配置的三个层次(优先级) 局部 ---> 项目 ---> drf默认
视图组件(5星)
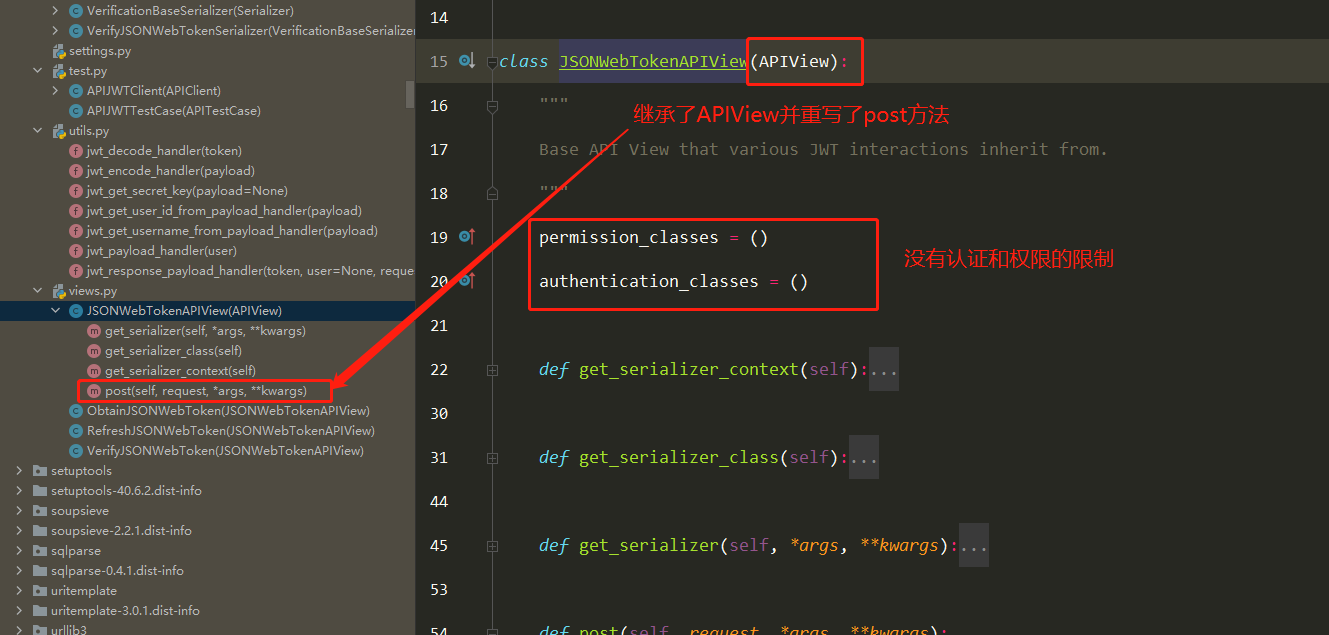
两个视图基类 APIView APIView与View的区别
传入到视图方法中的是rest-framework的Request类的request对象,而不是Django的HttpResponse对象
视图方法返回的是rest-framework的Response类的response对象,视图会因为响应数据设置(rander)符合前端要求的格式
任何APIException异常都会被捕获到,并处理成合适的响应信息
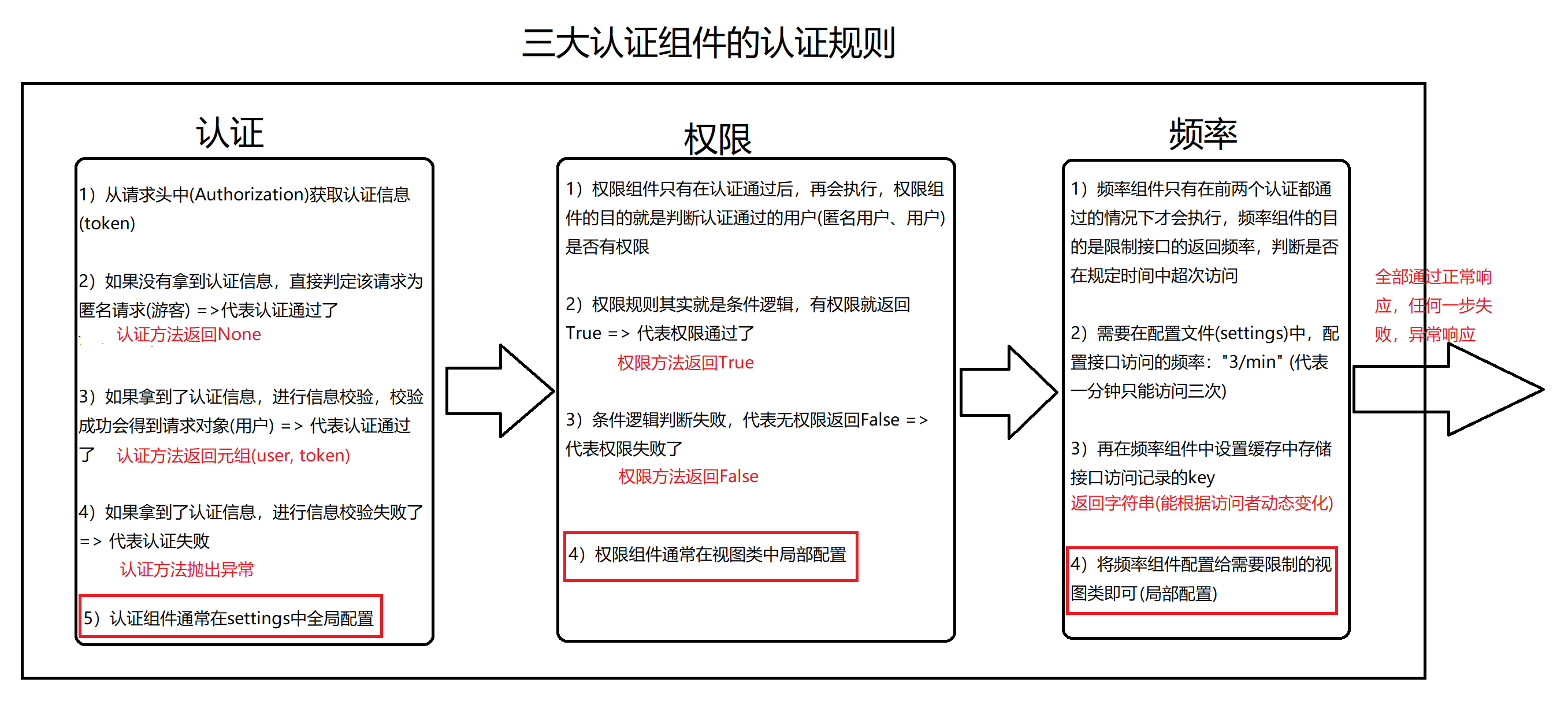
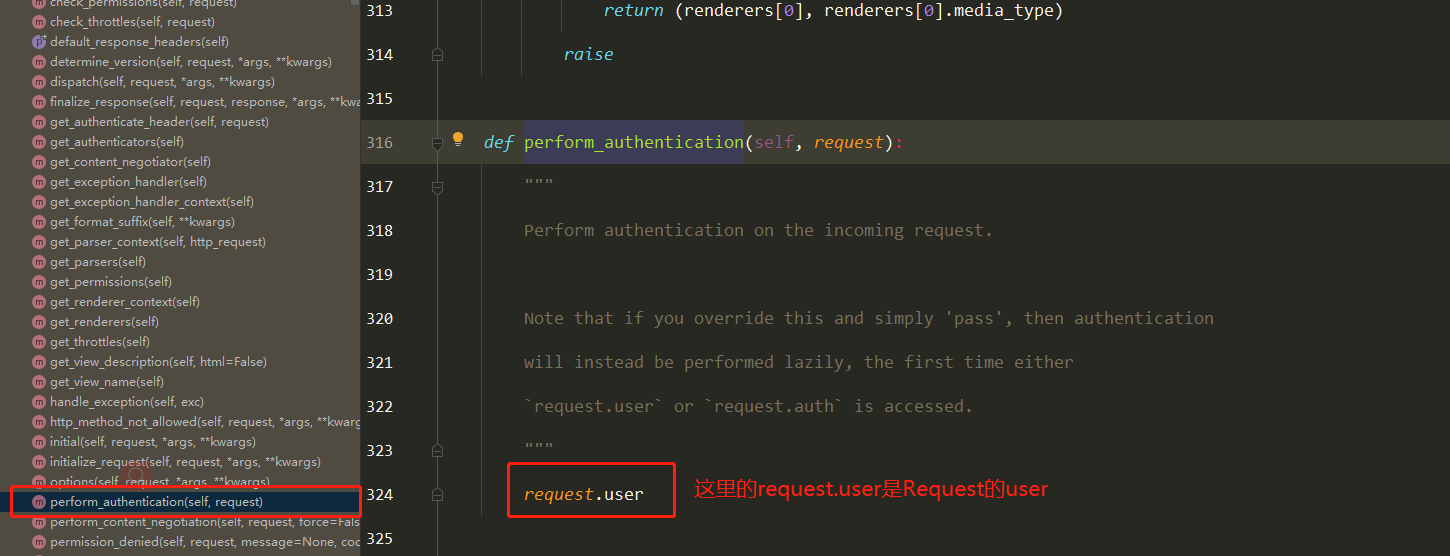
在进行dispatch()分发前,会对请求进行身份认证、权限检查、流量控制
支持定义的类属性
authentication_classes列表或元组(身份认证类)
permissoin_classes列表或元组(权限检查类)
throttle_classes列表或元组(流量/频率控制类)
GenericAPIView(通用视图类) 1 2 3 4 5 ''' 涉及到数据库操作,尽量选择GenericAPIView,减少代码量 '''
提供的关于序列化器使用的属性与方法
属性
==serializer_class== : 指明视图使用的序列化器
方法
==get_serializer_class(self)== : 当出现一个视图类中调用多个序列化器时,可以通过条件判断get_serializer_class方法中通过返回不同的序列器类名,就可以让视图方法执行不同的序列化器对象了
==get_serializer(self, *args, **kwargs)== : 返回序列化器对象,主要用来提供给Mixin扩展类使用(该方法在提供序列化器对象的时候,会向序列化器对象的context属性补充三个数据:request、format、view,这三个数据对象可以在定义序列化器时使用)(可以传instance、data、many)
request :当前视图的请求对象
view :当前请求的类视图对象
format :当前请求期望返回的数据格式
提供的关于数据库查询的属性与方法
属性
==queryset== :查询的表名.objects.all() (这里不写all会自动添加上all,但推荐都写上)
方法
==get_queryset(self)== :获取查询需要用到的所有数据
==get_object(self)== :获取查询需要用到的单条数据 (若详情访问的模型类对象不存在,会返回404)
五个视图扩展类 这五个扩展类需要搭配GenericAPIView父类,因为五个扩展类的实现需要调用GenericAPIView提供的序列化器与数据库查询的方法
CreateModelMixin
ListModelMixin
DestroyModelMixin
UpdateModelMixin
RetrieveModelMixin
九个视图子类 ListAPIView
CreateAPIView
UpdateAPIView
DestroyAPIView
RetrieveAPIView
ListCreateAPIView
RetrieveUpdateDestroyAPIView
RetrieveDestroyAPIView
RetrieveUpdateAPIView
视图集 ViewSetMixin
1 2 3 4 5 6 7 8 例 path('books/' , views.BookView.as_view({'get' :'list' ,'post' :'create' }))
ViewSet
继承自APIView与ViewSetMixin,作用与APIView类似,提供了身份认证、权限校验、流量管理…
主要通过继承ViewSetMixin来实现在调用as_view()时传入字典的映射处理
没有提供任何动作action方法,需要我们自己实现action方法
需要自己编写list、retrieve、create、update、destroy等方法
GeneriViewSet
继承自GenericAPIView与ViewSetMixin
实现了调用as_view()时传入字典的映射处理
提供了GenericAPIView提供的基础方法,可以直接搭配Mixin扩展类使用
ModelViewSet
继承自GenericViewSet,包括了五个视图扩展类
ReadOnlyModelViewSet
继承自GenericViewSet,包括了ListModelMixin、RetrieveModelMixin
路由组件(5星) Routers 对于视图集ViewSet,我们除了可以自己手动指明请求方式与动作action之间的对应关系外,还可以使用Routers来快速实现路由创建
使用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from django.contrib import adminfrom django.urls import path, includefrom app01 import viewsfrom rest_framework.routers import SimpleRouterrouter = SimpleRouter() router.register('book' , views.Book_modelviewset) router.register('publish' , views.Publish_modelviewset) router.register('' , views.Login, basename='login' ) urlpatterns = [ path('admin/' , admin.site.urls), path('' , include(router.urls)) ] urlpatterns += router.urls
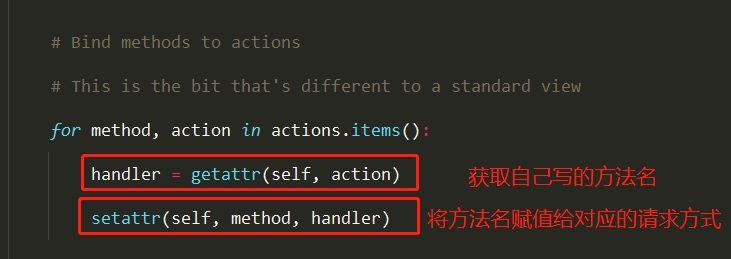
试图类中派生的方法,自动生成路由(action) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Login (ViewSetMixin, APIView ): authentication_classes = [] permission_classes = [] @action(methods=['POST' ], detail=False ) def login (self, request, *args, **kwargs ): username = request.data.get('username' ) password = request.data.get('password' ) user_alive = models.User.objects.filter (username=username, password=password).first() if user_alive: token = uuid.uuid4() models.User_token.objects.update_or_create(defaults={'token' :token}, user=user_alive) return Response({'code' :100 , 'msg' :'登录成功' , 'token' :token}, headers={'token' :token}) else : return Response({'code' :101 , 'msg' :'登录失败' }) ''' 参数解释: method: 用来指定请求方式,默认GET detail: 用来指定是否传入pk值(如:查所有或查单条),False:不传pk,True:传pk url_path: 用来指定url的路径,默认方法名 url_name: 用来指定url的别名 ''' ''' 注意: 1 如果继承了APIView,那么想要自动创建路由,则必须写action动作并在urls.py中传basename参数来指定视图 2 必须继承ViewSetMixin '''
认证组件(5星) 判断用户是否登录
简单使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from rest_framework.authentication import BaseAuthenticationfrom rest_framework.exceptions import AuthenticationFailedfrom app01 import modelsclass Login_authentication (BaseAuthentication ): def authenticate (self, request ): token = request.META.get('HTTP_TOKEN' ) user_token = models.User_token.objects.filter (token=token).first() if user_token: return user_token.user, token else : raise AuthenticationFailed('请先登录' ) class Login (ViewSetMixin, APIView ): authentication_classes = [Login_authentication] @action(methods=['POST' ], detail=False ) def login (self, request, *args, **kwargs ): username = request.data.get('username' ) password = request.data.get('password' ) user_alive = models.User.objects.filter (username=username, password=password).first() if user_alive: token = uuid.uuid4() models.User_token.objects.update_or_create(defaults={'token' :token}, user=user_alive) return Response({'code' :100 , 'msg' :'登录成功' , 'token' :token}, headers={'token' :token}) else : return Response({'code' :101 , 'msg' :'登录失败' }) ''' 全局配置: REST_FRAMEWORK = { 'DEFAULT_AUTHENTICATION_CLASSES':[ 'app01.auth.Login_authentication' ] } 局部禁用: authentication_classes = [] '''
源码分析
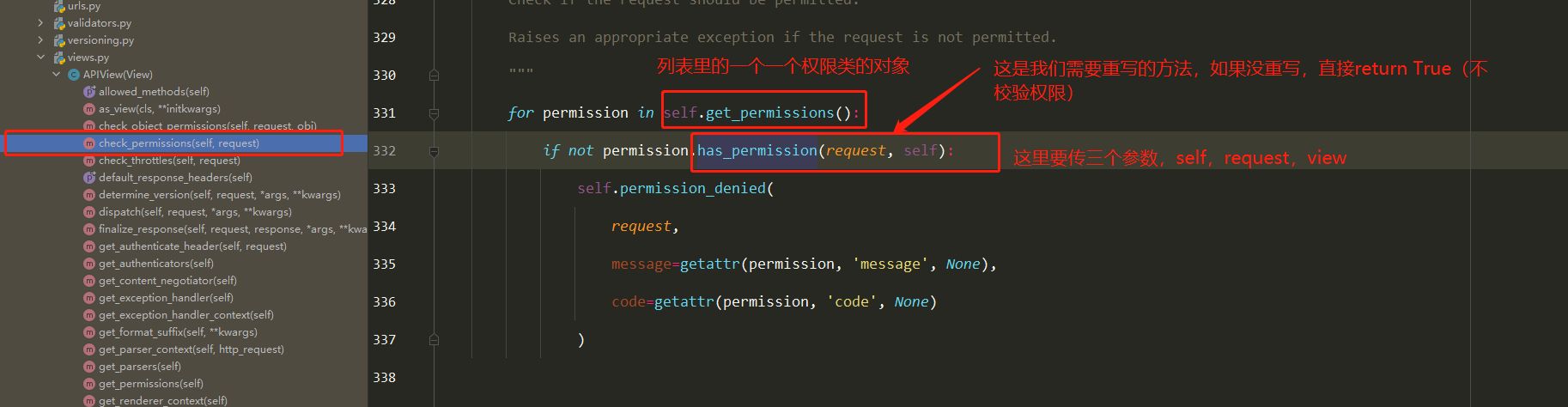
权限组件(4星) 简单使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from rest_framework.exceptions import PermissionDeniedfrom rest_framework.permissions import BasePermissionfrom app01 import modelsclass User_permission (BasePermission ): def has_permission (self, request, view ): if models.User.user_type == 1 : return True else : raise PermissionDenied(request.user.get_user_type_display()+'权限不够' ) class Login (ViewSetMixin, APIView ): permission_classes = [User_permission] @action(methods=['POST' ], detail=False ) def login (self, request, *args, **kwargs ): username = request.data.get('username' ) password = request.data.get('password' ) user_alive = models.User.objects.filter (username=username, password=password).first() if user_alive: token = uuid.uuid4() models.User_token.objects.update_or_create(defaults={'token' :token}, user=user_alive) return Response({'code' :100 , 'msg' :'登录成功' , 'token' :token}, headers={'token' :token}) else : return Response({'code' :101 , 'msg' :'登录失败' }) ''' 全局配置: REST_FRAMEWORK = { 'DEFAULT_PERMISSION_CLASSES':[ 'app01.auth.User_permission' ] } 局部禁用: permission_classes = [] '''
源码分析
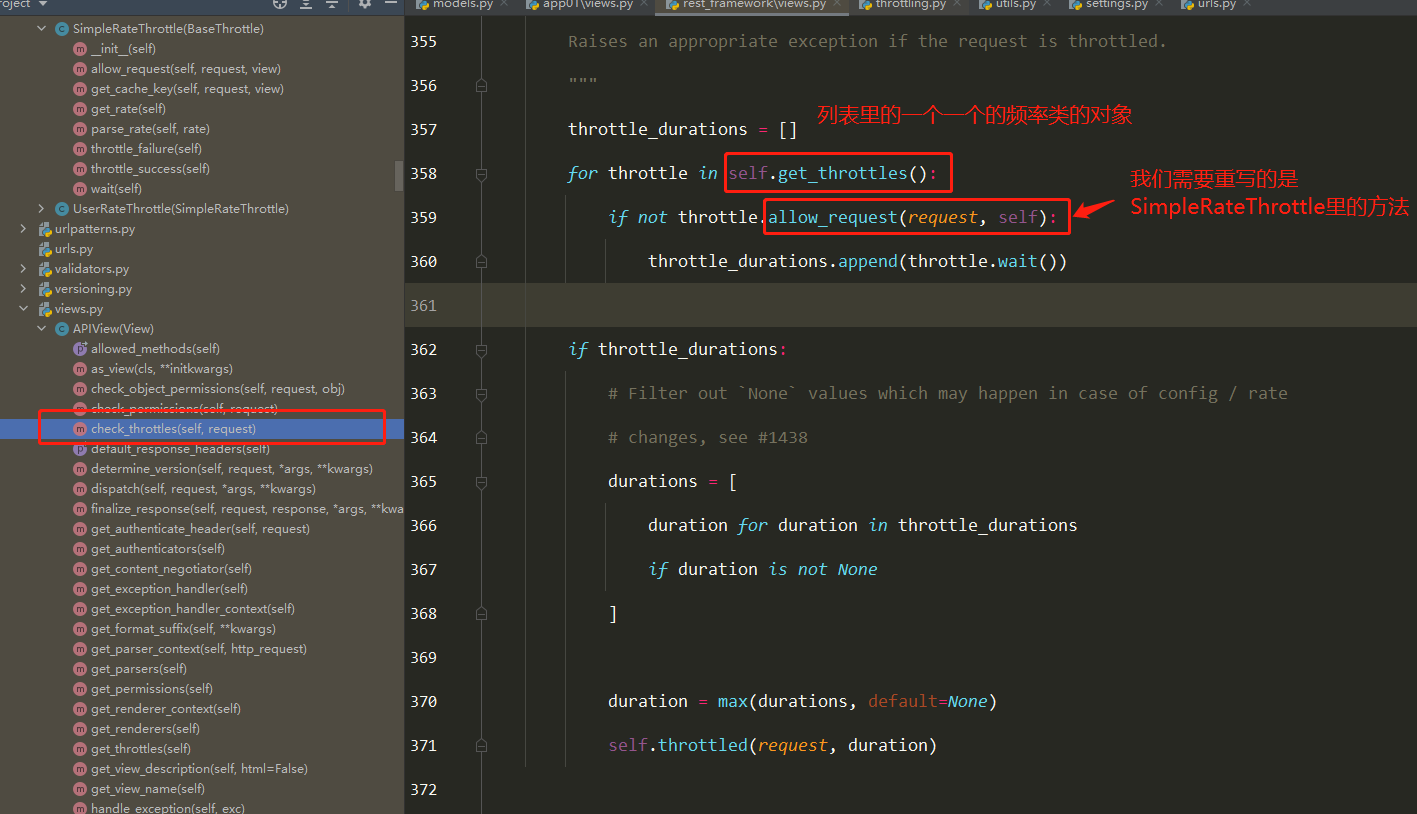
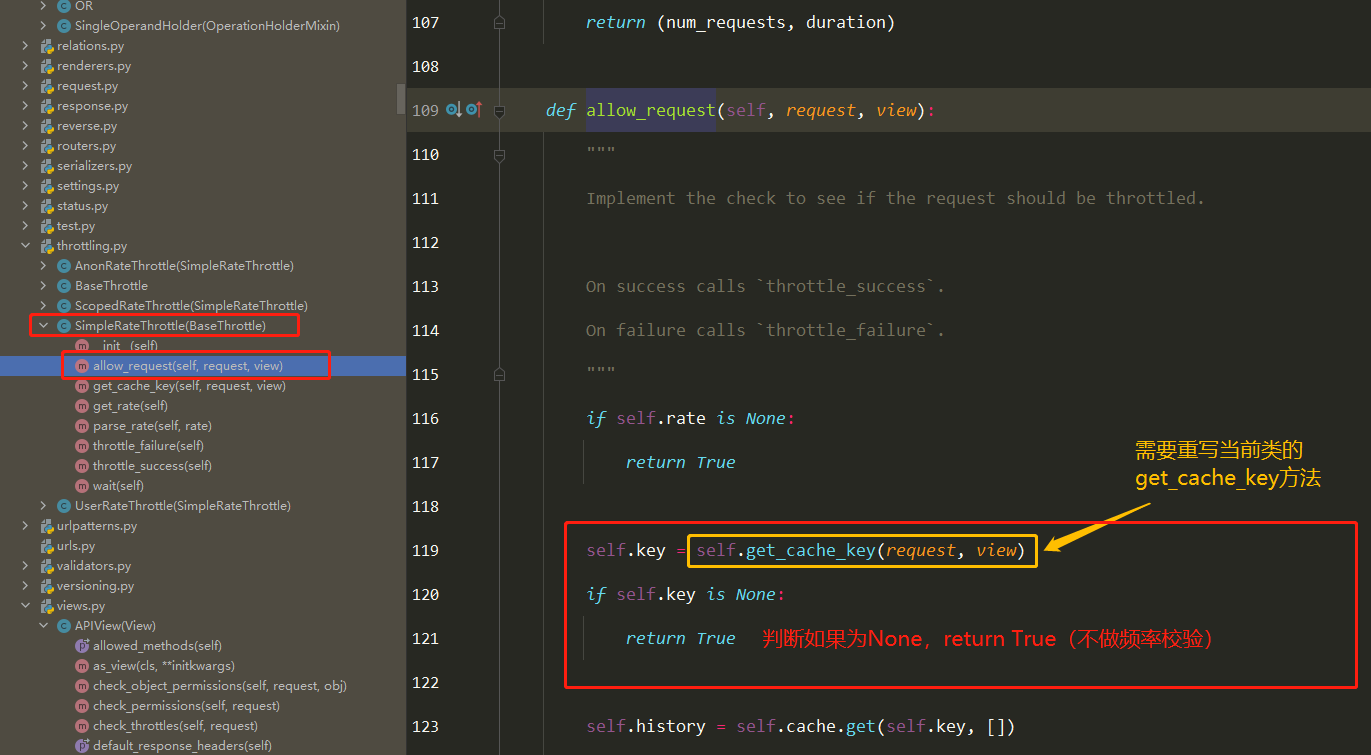
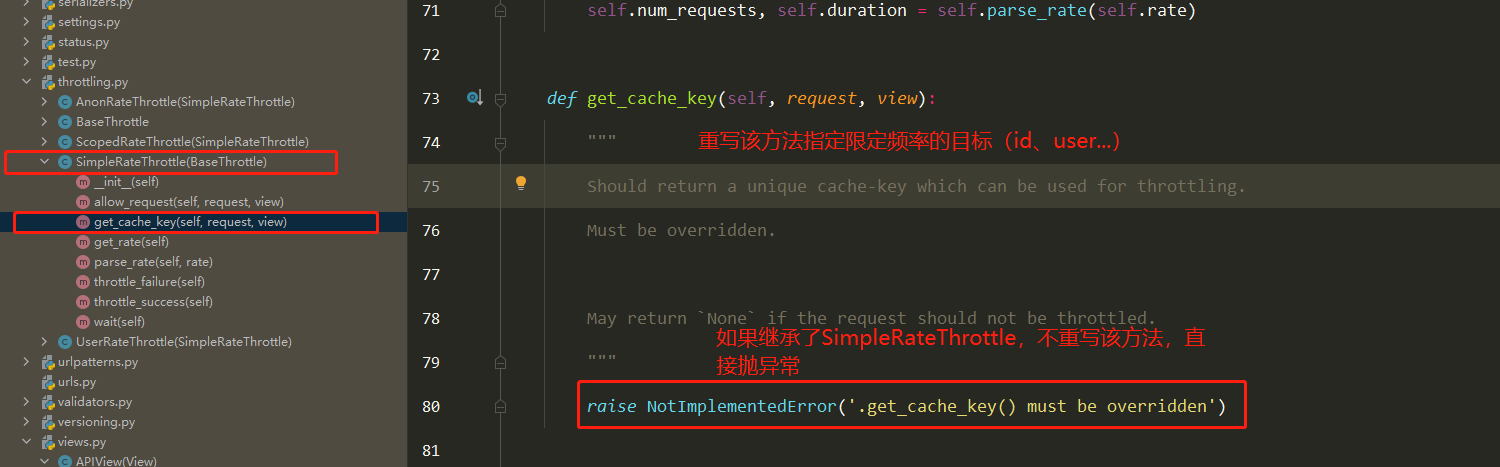
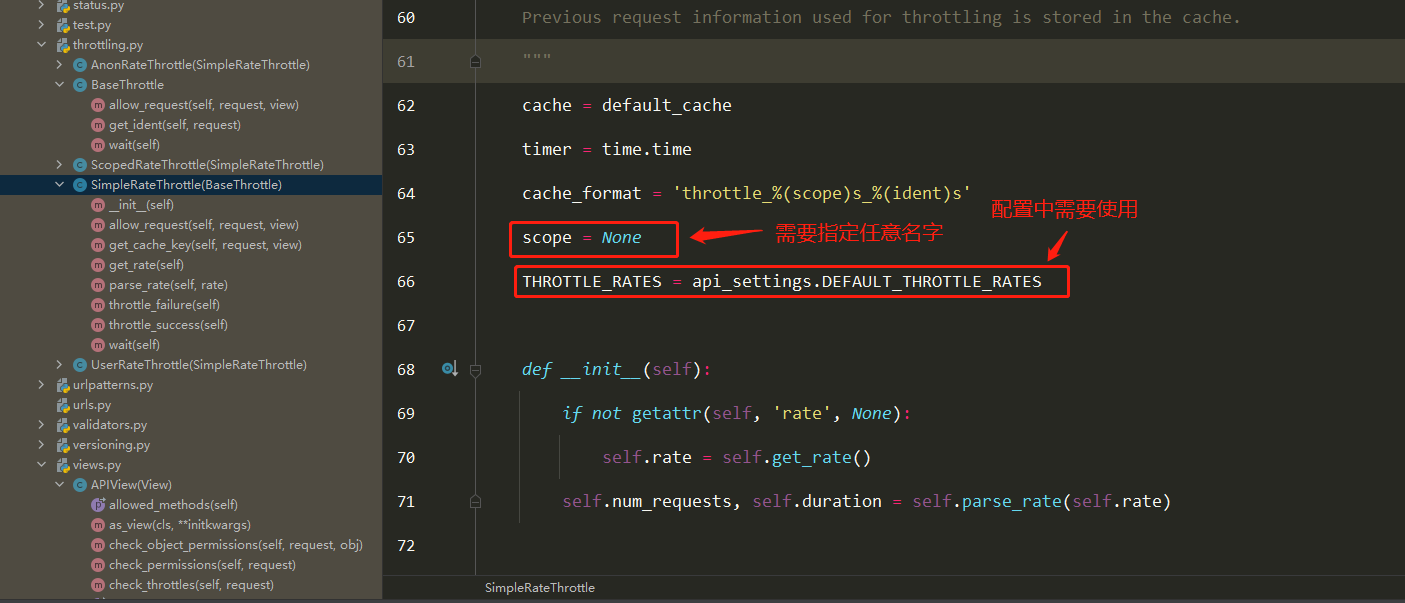
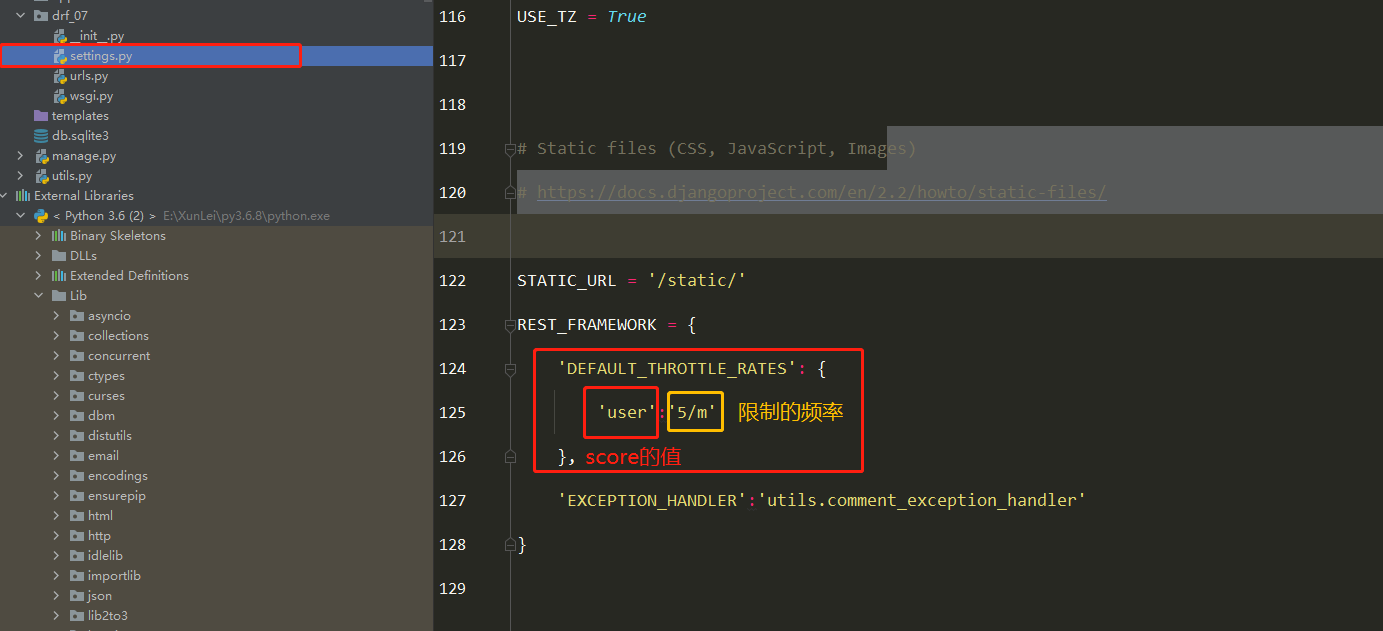
频率组件(5星) 自定义频率类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class MyThrottles (): VISIT_RECORD = {} def __init__ (self ): self.history=None def allow_request (self,request, view ): ip=request.META.get('REMOTE_ADDR' ) import time ctime=time.time() if ip not in self.VISIT_RECORD: self.VISIT_RECORD[ip]=[ctime,] return True self.history=self.VISIT_RECORD.get(ip) while self.history and ctime-self.history[-1 ]>60 : self.history.pop() if len (self.history)<3 : self.history.insert(0 ,ctime) return True else : return False def wait (self ): import time ctime=time.time() return 60 -(ctime-self.history[-1 ])
简单使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class User_throttle (SimpleRateThrottle ): scope = 'user' def get_cache_key (self, request, view ): return request.user.username throttle_classes = [User_base_throttle,] REST_FRAMEWORK = { 'DEFAULT_THROTTLE_RATES' : { 'user' :'5/m' }, } throttle_classes = []
源码分析
过滤与排序(4星) 简单使用 ==查询所有==才需要过滤(根据条件过滤),排序(按某个规则排序)
内置类使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from rest_framework.filters import SearchFilterclass BookView (ViewSetMixin,ListAPIView ): filter_backends = [SearchFilter,] search_fields=['name' ,'publish' ] http://127.0 .0 .1 :8000 /books/?search=达 from rest_framework.filters import OrderingFilter,SearchFilterclass BookView (ViewSetMixin,ListAPIView ): filter_backends = [SearchFilter,OrderingFilter,] search_fields=['name' ] ordering_fields=['price' ,'id' ] http://127.0 .0 .1 :8000 /books/?ordering=price,-id
第三方插件使用(django-filter)
1 2 3 4 5 6 7 8 9 10 11 12 13 from django_filters.rest_framework import DjangoFilterBackendclass BookView (ViewSetMixin,ListAPIView ): filter_backends = [DjangoFilterBackend,] filter_fields=['name' ,'price' ] http://127.0 .0 .1 :8000 /books/?name=红楼梦 http://127.0 .0 .1 :8000 /books/?name=四方达&price=15
异常处理(4星) 简单使用 全局统一捕获异常,返回固定的格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 1 写一个函数 2 在配置文件中配置 1 写函数: from rest_framework.views import exception_handler from rest_framework.response import Response def comment_exception_handler (exc, context ): response = exception_handler(exc, context) if response: data = { 'code' :1001 , 'msg' :'错误' , 'detail' :response.data } return Response(data) else : data = { 'code' :1002 , 'msg' :'未知错误' } return Response(data) 2 在配置文件中配置 REST_FRAMEWORK = { 'EXCEPTION_HANDLER' :'utils.comment_exception_handler' }
分页功能(5星) 查询所有,才有分页功能(例如网站的下一页功能,app的下滑加载更多)
重要类属性
page_size = api_settings.PAGE_SIZE (每页显示条数)
page_query_param = ‘page’ (查询时用的参数)
page_size_query_param = None (更改返回条数)
max_page_size = None (每页最大显示条数)
使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class CommonPageNumberPagination (PageNumberPagination ): page_size = 2 page_query_param = 'page' page_size_query_param = 'search' max_page_size = 5 class BookAPIView (ViewSetMixin, ListAPIView ): queryset = models.Books.objects.all () serializer_class = BookModelSerializer pagination_class = CommonPageNumberPagination
重要的类属性
default_limit = api_settings.PAGE_SIZE (每页显示条数)
limit_query_param = ‘limit’ (查询时用的参数)
offset_query_param = ‘offset’ (offset偏移的查询参数)
max_limit = None (每页最大显示条数)
使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class CommonLimitOffsetPagination (LimitOffsetPagination ): default_limit = 3 limit_query_param = 'limit' offset_query_param = 'offset' max_limit = 5 class BookAPIView (ViewSetMixin, ListAPIView ): queryset = models.Books.objects.all () serializer_class = BookModelSerializer pagination_class = CommonLimitOffsetPagination
重要的类属性
cursor_query_param = ‘cursor’ (查询条件)
page_size = api_settings.PAGE_SIZE (每页显示条数)
ordering = ‘-created’ (排序)
page_size_query_param = None (更改每页显示条数)
max_page_size = None (每页最大显示条数)
使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class CommonCursorPagination (CursorPagination ): cursor_query_param = 'cursor' page_size = 2 ordering = '-id' page_size_query_param = 'offset' max_page_size = 5 class BookAPIView (ViewSetMixin, ListAPIView ): queryset = models.Books.objects.all () serializer_class = BookModelSerializer pagination_class = CommonCursorPagination
继承APIView实现三种分页方式 1 2 3 4 5 6 7 class BookAPIView2 (APIView ): def get (self, request, *args, **kwargs ): book_list = models.Books.objects.all () pagination = CommonPageNumberPagination() book_list2 = pagination.paginate_queryset(book_list, request, self) ser = BookModelSerializer(instance=book_list2, many=True ) return pagination.get_paginated_response(ser.data)
自动生成接口文档(3星)
使用coreapi自动生成 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from rest_framework.documentation import include_docs_urlsurlpatterns = [ path('docs/' , include_docs_urls(title='查询所有' )), ] REST_FRAMEWORK = { 'DEFAULT_SCHEMA_CLASS' : 'rest_framework.schemas.coreapi.AutoSchema' , } ps:'DEFAULT_SCHEMA_CLASS' : 'rest_framework.schemas.openapi.AutoSchema' , ps:extra_kwargs = { '字段' :{'help_text' :'xxxx' } }
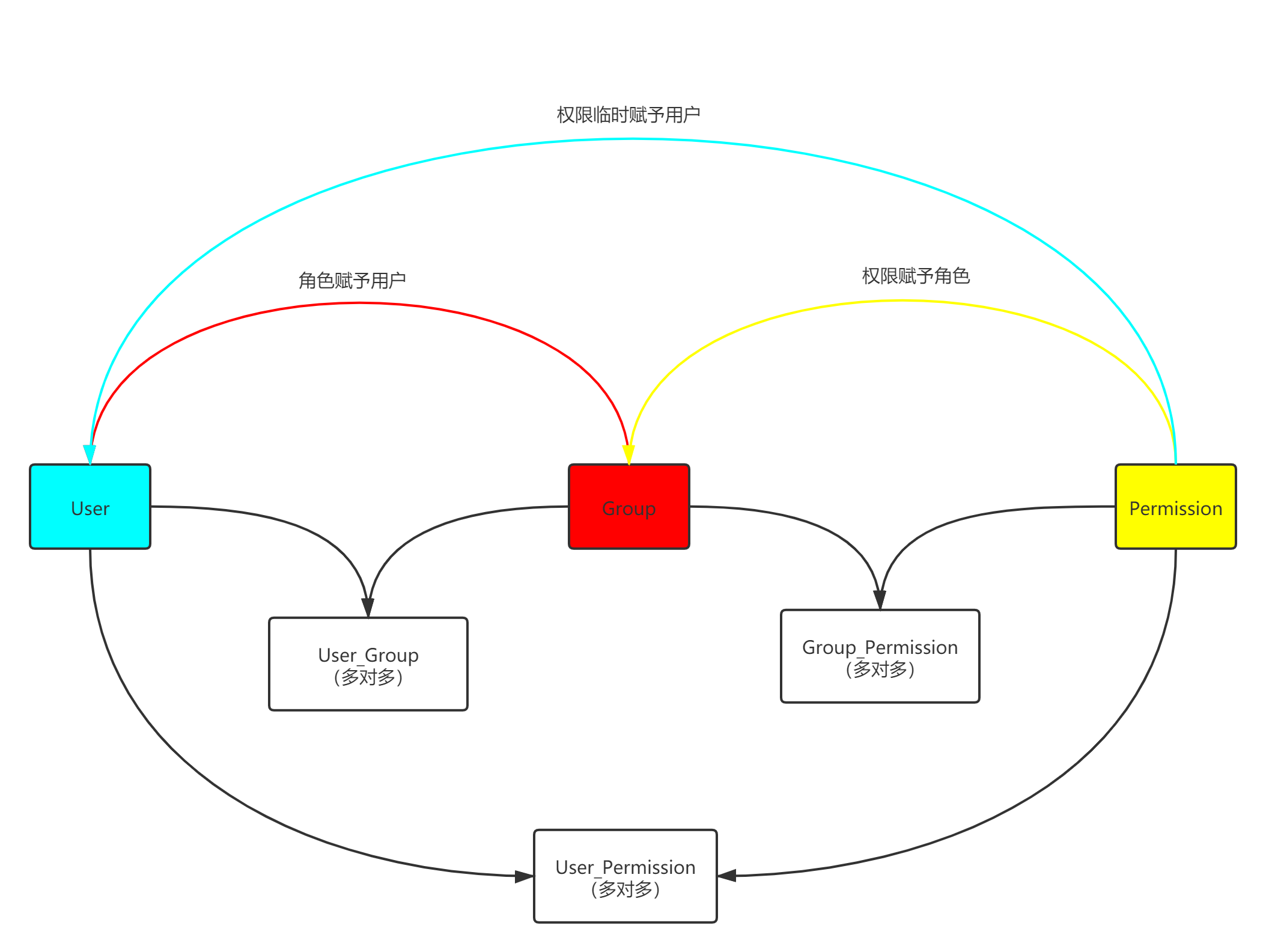
RBAC(4星)
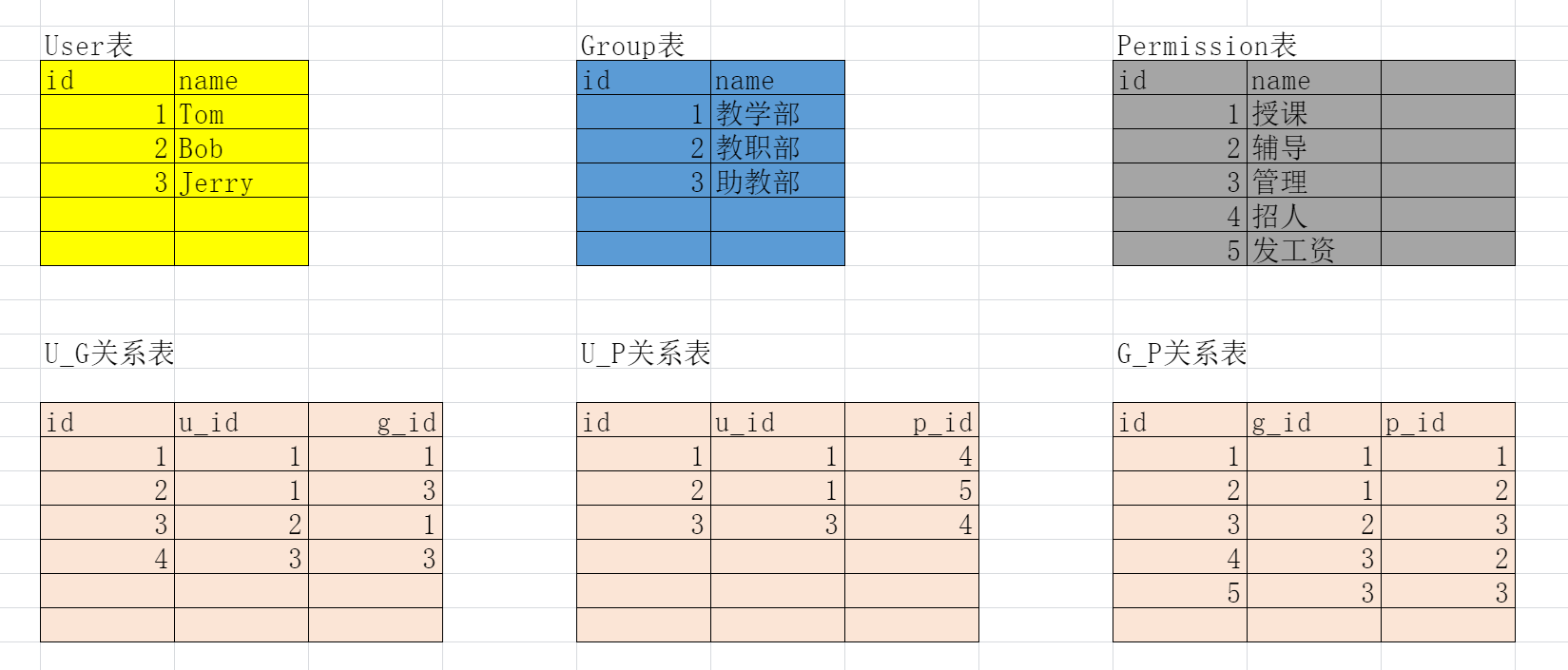
RBAC:Role-Based Access Control (基于角色的访问控制)
原理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1 User表 :存用户信息 2 Permission表 :存权限 3 Role表 :存角色(组) 4 Group_Role中间表 :权限赋予角色(多对多) 5 User_Group中间表 :角色赋予用户(多对多) 6 User_Permission中间表 :权限临时赋予角色(多对多) ''' ps: 1 Django后台管理admin自带RBAC 2 基于admin做二次开发(simple-ui) 3 基于前后端分离实现RBAC(https://github.com/liqianglog/django-vue-admin) 4 前后端混合的后台前端模板(X-admin--->快速开发后台管理系统) 5 智慧大屏(https://gitee.com/kevin_chou/dataVIS.git) '''
JWT(5星) 介绍(5星) Json Web Token(JWT):一种前后端的认证方式
构成和工作原理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 header(头):认证方式,加密方式,公司名字... { 'typ' :'JWT' , 'alg' :'HS256' } payload(荷载):用户信息,过期时间,签发时间... { "userid" :"2" , "name" :"Jerry" , "exp" :121456 } signature(签名):把前面的头和荷载通过设置好的加密方式得到的串 1 用户登录成功: 1.1 构造token的头(固定) 1.2 构造荷载 1.3 使用设置好的加密方式对头和荷载加密,得到签名,三者用.拼接起来,生成一个token串(使用base64编码) 例如: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ 2 用户携带token,来到后端,把头和荷载再使用相同的加密方式加密,得到签名,比较新签名和旧签名是否一致,如果一致,说明该token可以信任,解析出当前用户(荷载),继续往后走
base64编码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import base64import jsondic={'name' :'lqz' ,'id' :1 } user_info_str=json.dumps(dic) res=base64.b64encode(user_info_str.encode('utf-8' )) print (res) res=base64.b64decode('TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ=' .encode('utf-8' )) print (res)''' ps: base64长度是4的倍数,如果不足,需要用=号补齐 '''
JWT快速使用(2星) 使用第三方:
签发
1 2 3 4 5 6 7 path('login/' , obtain_jwt_token)
认证
1 2 3 4 5 6 7 8 9 10 11 12 from rest_framework_jwt.authentication import JSONWebTokenAuthenticationfrom rest_framework.permissions import IsAuthenticatedclass BookView (ViewSetMixin,ListAPIView ): authentication_classes = [JSONWebTokenAuthentication,] permission_classes = [IsAuthenticated,] key:Authorization value:jwt xxx(以空格切割取token)
JWT使用auth表签发token,自定制格式(3星) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def jwt_response_payload_handler (token, user=None , request=None ): return { 'code' :100 , 'msg' :'登录成功' , 'username' :user.username, 'token' : token, } JWT_AUTH ={ 'JWT_EXPIRATION_DELTA' : datetime.timedelta(days=7 ), 'JWT_RESPONSE_PAYLOAD_HANDLER' : 'app01.utils.jwt_response_payload_handler' , }
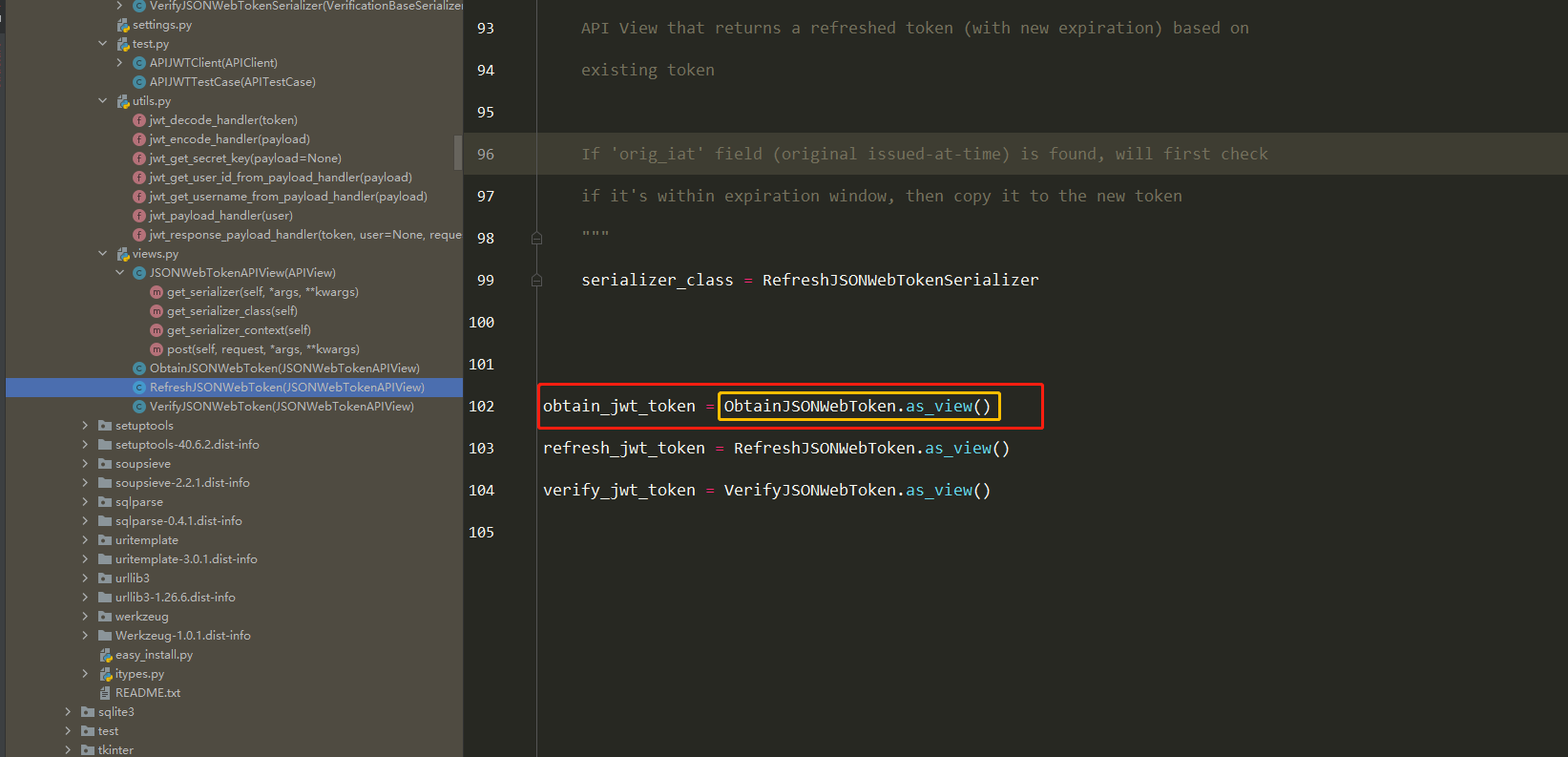
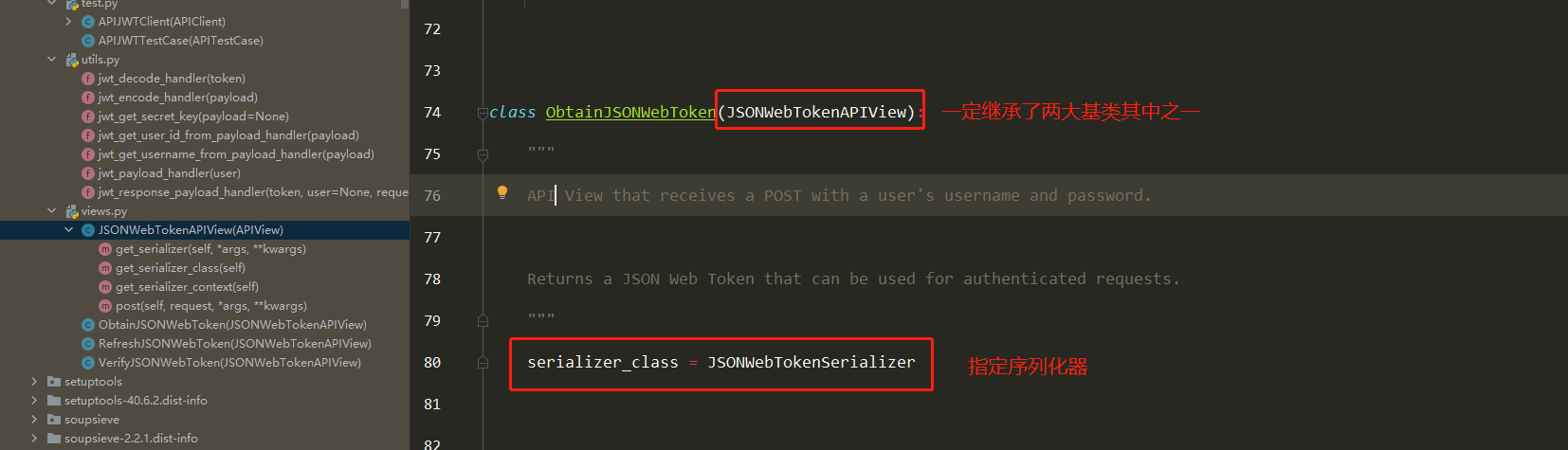
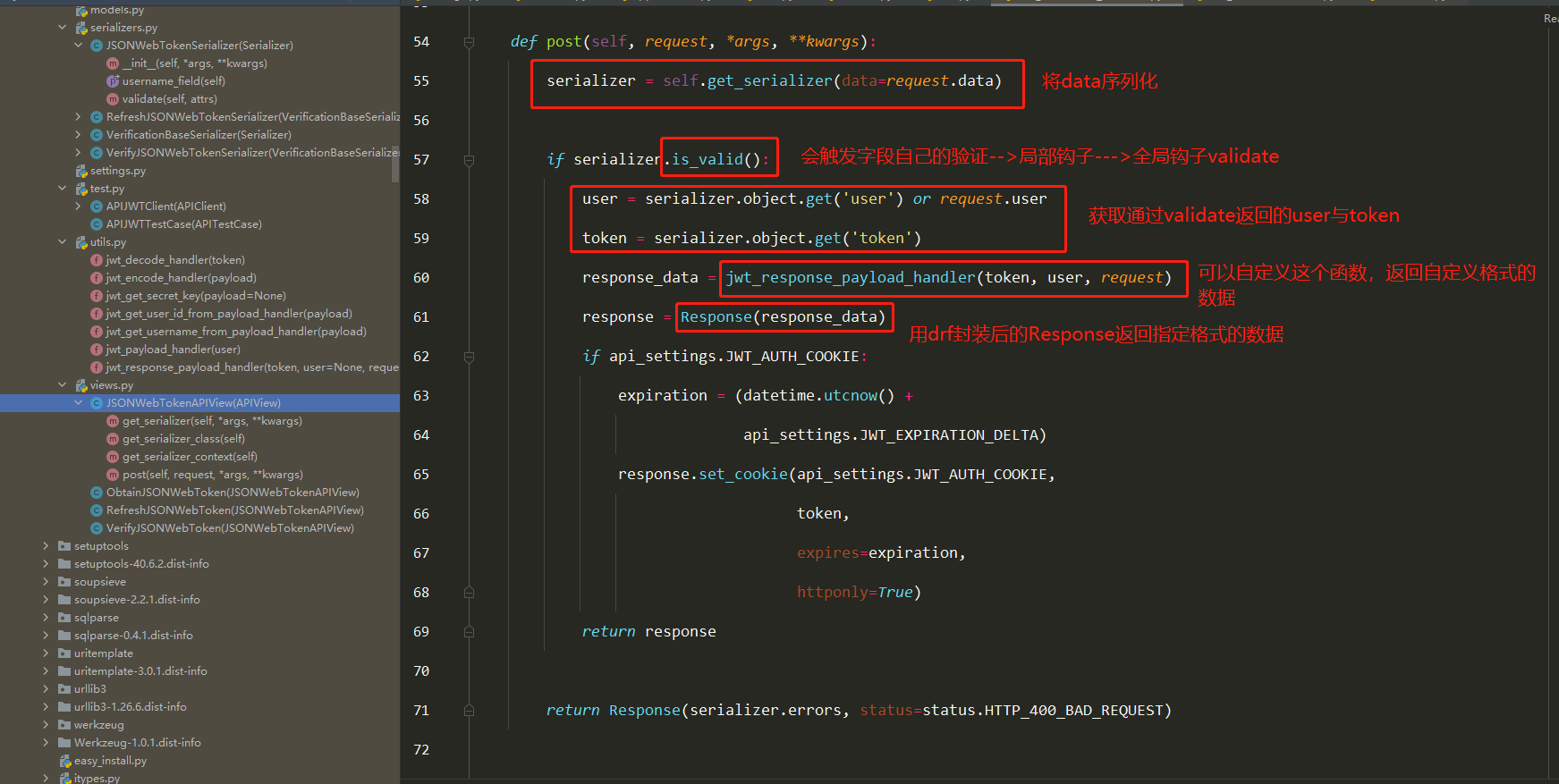
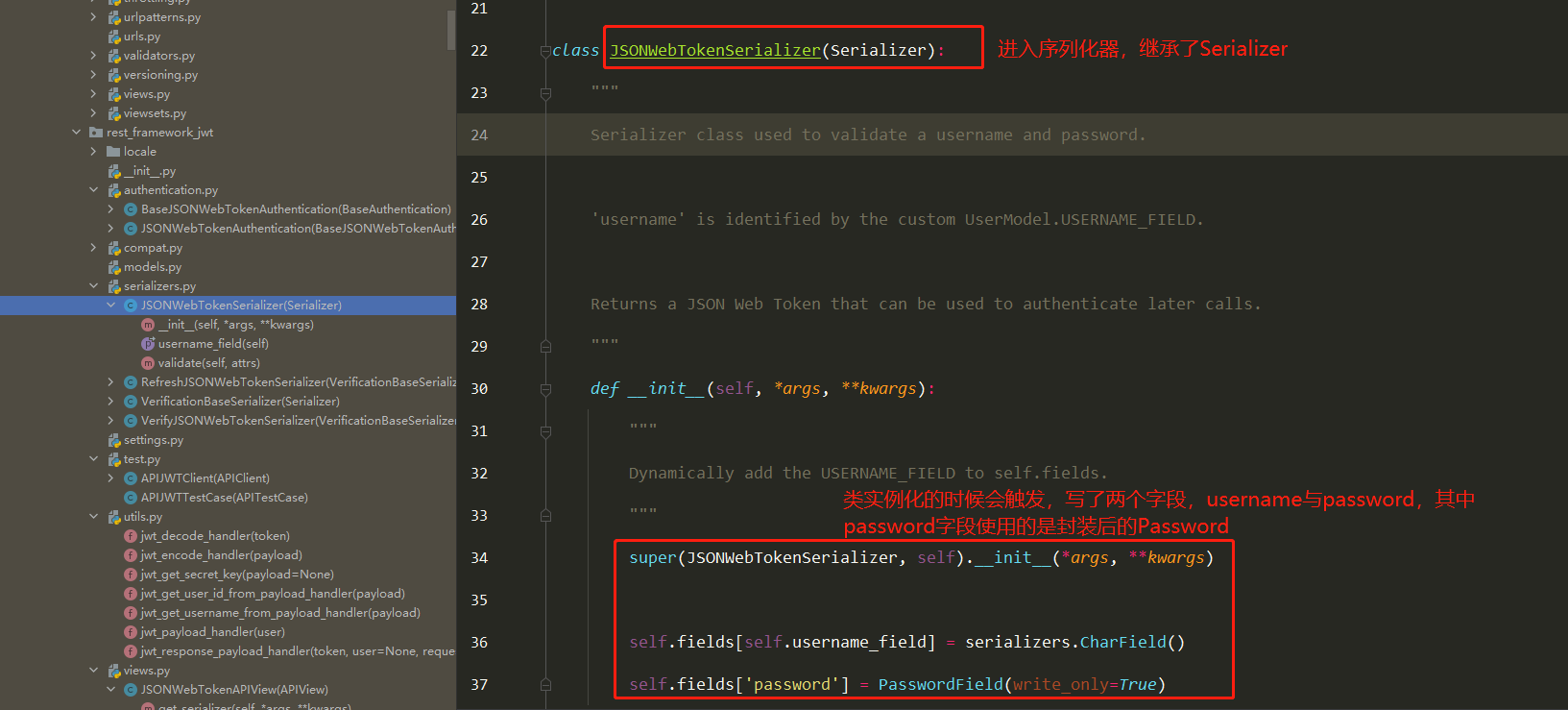
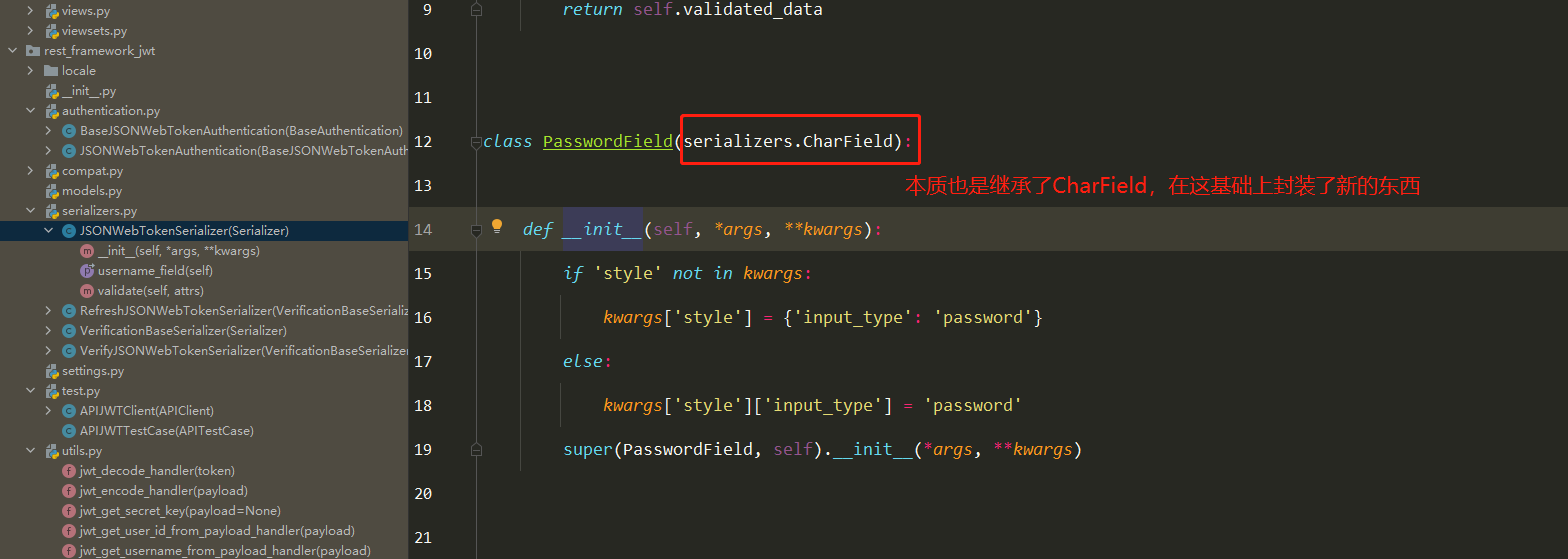
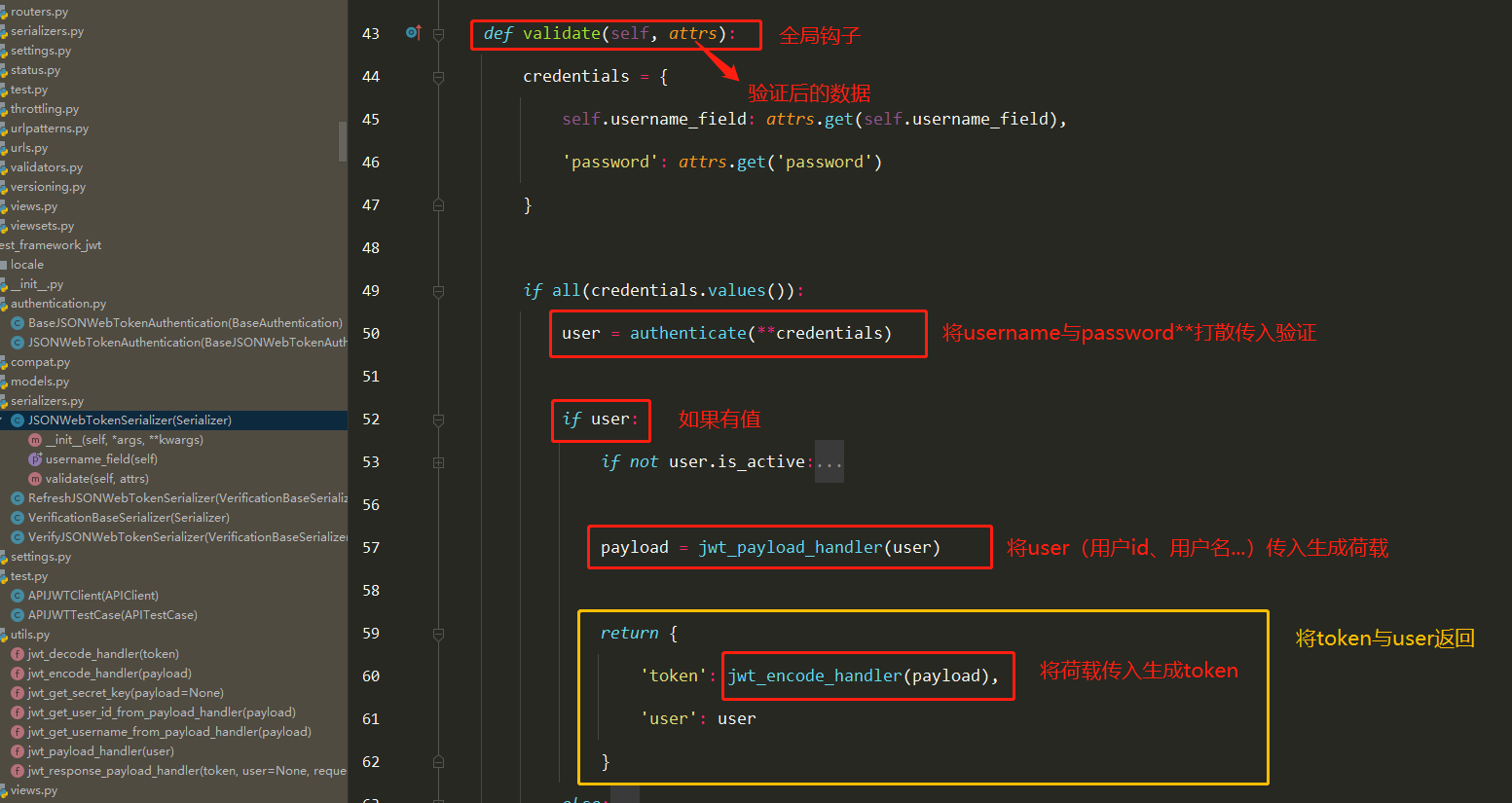
obtain_jwt_token源码分析(2星)
基于jwt的认证类(5星) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 ''' 重点逻辑在authenticate方法中: 1 取出客户端传入的token(后端自己规定是从头/路径中拿) 2 验证jwt的签名(使用模块提供的) 3 通过payload得到当前登录用户对象(使用模块提供的) 4 返回user,token ''' class JWTAuthentication (BaseJSONWebTokenAuthentication ): def authenticate (self, request ): print (request.META) token=request.META.get('HTTP_AUTHORIZATION' ,None ) if token: try : payload = jwt_decode_handler(token) except jwt.ExpiredSignature: raise AuthenticationFailed('token过期' ) except jwt.DecodeError: raise AuthenticationFailed('token认证失败' ) except jwt.InvalidTokenError: raise AuthenticationFailed('token不合法' ) else : raise AuthenticationFailed('token没有携带' ) user = self.authenticate_credentials(payload) return (user, token) ''' 三种方式得到user: 1 继承,直接使用该类的方法 2 把方法copy出来,导入一箩筐 3 完全自己写(copy出来改吧改吧) '''
基于自定义User表,签发token(5星) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 router=SimpleRouter() router.register('books' ,views.BookView) router.register('user' ,views.UserInfoView,basename='user' ) urlpatterns = [ path('' , include(router.urls)), ] class UserInfoView (ViewSet ): @action(methods=['POST' ],detail=False ) def login (self,request ): username=request.data.get('username' ) password=request.data.get('password' ) res={'code' :'100' ,'msg' :'登录成功' } user=User.objects.filter (username=username,password=password).first() if user: payload = jwt_payload_handler(user) token=jwt_encode_handler(payload) res['token' ]=token else : res['code' ]=101 res['msg' ]='用户名或密码错误' return Response(res) class JWTMyUserAuthentication (BaseAuthentication ): def authenticate (self, request ): token=request.META.get('HTTP_AUTHORIZATION' ,None ) if token: try : payload = jwt_decode_handler(token) print (payload) except jwt.ExpiredSignature: raise AuthenticationFailed('token过期' ) except jwt.DecodeError: raise AuthenticationFailed('token认证失败' ) except jwt.InvalidTokenError: raise AuthenticationFailed('token不合法' ) else : raise AuthenticationFailed('token没有携带' ) user=User.objects.get(pk=payload.get('user_id' )) return (user, token)
多方式登录(5星) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 1 使用用户名、邮箱、手机号 + 密码都能登录成功2 可以使用auth的User表,也可以自定义用户表3 扩写auth的User表(没有迁移之前使用--->继承AbstractUser) 硬写: 3.1 删库(要有备份) 3.2 删除迁移记录(app的迁移记录,auth、admin的迁移记录(源码中)) class Userinfo (ViewSet ): @action(methods=['POST' ], detail=False ) def login (self, request, *args, **kwargs ): response = {'code' :1000 , 'msg' :'登录成功' , 'token' :None } ser = UserModelSerializer(data=request.data) if ser.is_valid(): response['token' ] = ser.context.get('token' ) else : response['code' ] = 1001 response['msg' ] = ser.errors return Response(response) class UserModelSerializer (serializers.ModelSerializer ): username = serializers.CharField() class Meta : model = Userinfo fields = ['username' , 'password' ] def validate (self, attrs ): user = self._get_user(attrs) token = self._get_token(user) self.context['token' ] = token return attrs def _get_user (self, attrs ): username = attrs.get('username' ) password = attrs.get('password' ) if re.match('^1(3[0-9]|4[01456879]|5[0-35-9]|6[2567]|7[0-8]|8[0-9]|9[0-35-9])\d{8}$' , username): user = Userinfo.objects.filter (phone=username).first() elif re.match('^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$' , username): user = Userinfo.objects.filter (email=username).first() else : user = Userinfo.objects.filter (username=username).first() if user: if user.check_password(password): return user else :raise ValidationError('用户名或密码错误' ) else : raise ValidationError('用户名或密码错误' ) def _get_token (self, user ): payload = jwt_payload_handler(user) token = jwt_encode_handler(payload) return token class User_jwt_authentication (BaseJSONWebTokenAuthentication ): def authenticate (self, request ): token = request.META.get('HTTP_AUTHORIZATION' ) try : payload = jwt_decode_handler(token) except jwt.ExpiredSignature: raise AuthenticationFailed('签名过期,请重新登录' ) except jwt.DecodeError: raise AuthenticationFailed('认证错误' ) except jwt.InvalidTokenError: raise AuthenticationFailed('认证不合法' ) user = self.authenticate_credentials(payload) return (user, token) def authenticate_credentials (self, payload ): username = payload.get('username' ) if not username: raise AuthenticationFailed('用户名不存在' ) try : user = Userinfo.objects.filter (username=username).first() except Userinfo.DoesNotExist: raise AuthenticationFailed('无效的签名' ) if not user.is_active: raise AuthenticationFailed('用户已注销' ) return user